We continue to update the usage reports in the Office 365 admin center to provide you with a complete picture of how your organization is using Office 365. You’ll notice the following enhancements today.
The existing SharePoint activity report will be enhanced with additional user activity information (page views: number of pages a user has visited). The number of Files Shared internally and externally on the same report are being updated to fix a data issue.
The existing SharePoint site usage report will be enhanced with activity information from all site types (in addition to groups and team sites) and additional site activity information (page views: number of pages viewed in a site and number of unique pages visited in a site).
Due to this update, you’ll likely see a spike in activity in the SharePoint activity and the SharePoint site usage report. If you are using the Office 365 Adoption content pack in Power BI, you’ll also see a difference in the active user numbers for SharePoint between the data in the reports and the data in the content pack. Please follow the public Office Roadmap for more information about when the changes will be reflected in the Office 365 Adoption content pack.
Due to the fix, you’ll see a difference in the split of files shared internally and files shared externally.
We’re back with another edition of the Modern Service Management for Office 365 blog series! In this article, we review the evergreen cloud paradigm and considerations for an agile IT organization. These insights and best practices are brought to you by Carroll Moon, Senior Architect for Modern Service Management.
We have covered a lot of ground so far in this series from monitoring to sample code to the evolution of IT Pros and the IT Organization. Now, it is time to tackle “Evergreen Management.”
What is Evergreen Management?
In our industry, we have the bad habit of using the same terms for different things. For example, what is a domain? The answer depends on the context of the question. Are we talking about DNS, Active Directory, or something else? “Change Management” is an example of a term that means different things to different people.
Most of us think about change approvals and change advisory boards
Some of us think about the physical act of applying changes to servers
Others think about landing change on the humans and their desire to change their behaviors (like what we discussed in this blog post for IT Pros and what we will discuss in a forthcoming post for end-users)
At least a few of us think about change through the lens of “management of change within my cloud tenant”
Many of us think about “absorbing change from the cloud”
And I’m sure you have even more…
Let’s simplify the discussion by adding specificity. For the purpose of this blog post, we are going to avoid any confusion and discuss “Evergreen Management” instead of “Change Management.” We are defining “Evergreen Management” as the act of managing continuous evolution of features and functionality in the cloud to achieve business benefit while avoiding any adverse side effects. By the way, most people that I speak to are focused only on the “avoiding adverse side effects” side of the equation rather than on the “achieve business benefit” discussion. But as we covered in this blog post, the exciting future for IT Pros revolves around the business benefits. So, my goal is to help you spend most of your time on the business benefits while wrapping a lightweight process around the adverse-avoidance discussion.
The Release Continuum
In Office 365, there are many change classes and change types that we manage internally. With the customer lens, however, I prefer to simplify the discussion into four categories:
There is a class of change where we are confident that there will be NO impact to admins or end users. For example, we may move a mailbox for load balancing purposes. For this class of change, there is no need to communicate since there will be no impact to users or admins. Any directed communications to IT Pros or end-users would just be noise that would distract from important communications.
There is a class of change where we are confident that there WILL be impact to admins and/or end users. For example, if we change the behavior of a user’s inbox with a capability like Clutter. For this class of change, we communicate directly to IT Pros with directed communication to your tenant via Message Center (and via the Office 365 Service Communications API, Office 365 Mobile Admin, and SCOM Management Pack for Office 365). For the full story on IT Pro Communications scenarios for Office 365, see this blog post.
Now that we’ve dealt with both extremes, we are left with two, middle-of-the-road scenarios:
There is a class of change where impact is underestimated, and Microsoft gains additional insight through the feedback gathered during First Release deployment. For example, a minor UI change may not require downtime or obvious impact to a business, but it could generate more help desk calls than intended. Once we are aware of impact for some customers, we learn from the experience and communicate to other customers through Message Center. Minimization of customer impact is one of the beautiful things about deployment rings and first release. Microsoft learns and adapts in real time.
NOTE: One issue is that not enough customers are truly consuming the Message Center content, so even though there should be minimal impact with #3, often, there is broader impact because impacted customers did not consume the information. My hope with this blog post is that we fix that. I ask that everyone who reads this blog post will triage all Message Center posts (more about that topic below).
And finally:
There is a class of change where your unique situation will result in impact for you, but nobody else (or very few others) are in the same situation, so we are not able to predict it. For example, perhaps your order processing system has a firm dependency on the “free/busy” capability in Exchange Online and due to the way your application is written, perhaps there is a unique scenario where you see impact in your app when we deploy a new feature. This class is an extremely small subset, but as all of us who have been in IT very long know, Murphy and his law are always lurking. Even though this scenario is the anomaly, we should deal with it; let’s discuss how to address the scenario with lightweight business process.
NOTE: Of course, if a change causes downtime or behavior contrary to the design, we treat it as an incident. The incident discussion is covered in this blog post.
Some Thoughts About First Release
In the early days of Office 365, we did not have the concept of First Release. Later, we delivered the ability to turn on First Release at the tenant level. Tenant Level first release is ok for testing, but the problem is that none of us users really “kick the tires” on our test accounts like we do our production accounts. Because users do not use test accounts in the same way, tenant-level First Release did not adequately address scenario #3 above.
Later, we added First Release Specific-User to aim at scenario #3. I much prefer this option. Unfortunately though, many customers do not use First Release Specific-User for whatever reason. And for those customers who do use it, most use it only for IT Pros. Here’s the problem, if we re-look at scenario #3, the scenario is about your specific business applications and processes – something unique to you. Those processes are in your business groups (i.e. likely not in IT, but rather in marketing or some other business group). So, what I recommend is that every single Office 365 customer put a subset of their real, production, business-group users into First Release Specific User.
Here’s the great news: most customers have super-users in each department and in each location already. For on-premise Exchange, for example, there are super-users who are “in-the-know” for what is coming. Those super users test new features in the on-premise service. Those super-users give great feedback to IT. We just need to tap into the existing super-user relationships for the cloud. Put those people into First Release Specific-User.
NOTE: Even if you do not put any users into First Release with your production tenant, you should still enable First Release for Specific Users and leave the list null. That way, your production tenant will get the First Release communications via Message Center.
Lightweight Business Process
Ok, so now you have First Release for Specific-Users enabled, and you have real business users in the list. That is great. Thank you! You are way ahead of the game now for scenario #3 above. What’s next? I would recommend that you implement a lightweight cadence with those first-release-business-users as in the following example:
1. Establish a monthly cadence with the first-release-business-users
2. In the monthly meeting, triage the following data sources with your first-release-business-users
Message Center posts (tenant specific IT pro communications)
Roadmap.office.com (general awareness of what’s in development)
Blogs.office.com (news and announcements)
3. For each item triaged, discuss the following:
How can the super-user and the super-user’s department get great business value out of the new or changed feature? (and how will you measure the value?) Remember, our discussion about the future of IT this blog post
What issues could arise when the new or updated feature is introduced? What could break? Could it cause help desk calls?
4. Ensure an out-of-band meeting plan is in place. If Microsoft notifies you of a new capability that will deploy prior to your next scheduled meeting, there should be a pre-agreed plan to have an ad-hoc meeting with the same agenda of “B” and “C.”
5. Ensure that an easy-button is in place for the first-release-business-users to escalate directly to the right people in IT whenever they see something that may be a problem. Encourage those super-users to escalate early and quickly so that IT can get in front of any issues. Also, such seamless escalations will allow IT to escalate to Microsoft as needed.
Remember: you can consume the information in many ways, and ideally, as an enterprise, you will simply pull these communications into your existing monitoring tools and/or service management tools as covered this blog post.
My hope is that every one of you will take action to a) consume the information from Office 365 blogs, roadmap, and Message Center b) review the communications for business benefit and adversity-avoidance with your business users and c) to drive and measure business benefits of each new feature because success begets success like nothing else.
Next up: Service Desk and Normal Incident Management.
We are delighted today to announce the general availability of the Centralized Deployment service!
Centralized Deployment enables you as the Office 365 admin, to deploy Office web add-ins to individual users, groups or the organization from the Office 365 Admin Center or using PowerShell scripts. Once deployed, Office users can automatically see the add-in installed and ready to use in Office applications such as Word, Excel or PowerPoint on Windows, Mac or Office Online.
Centralized Deployment in Office 365 Admin Center
What you need to know
Support for Windows, Mac and Office Online – for Word, Excel and PowerPoint
Add-Ins are automatically deployed on client boot
If the Add-In supports Add-In Commands, its buttons will appear automatically on the ribbon.
Use Office Admin Center or PowerShell
Use either Office 365 Admin Center or PowerShell to deploy, assign and modify Add-Ins
Acquire add-ins from Store or Directly via manifest
Acquire and assign from the Office Store if the manifest is same across users
Upload via add-in manifest when for example a custom add-in is developed internally for your organizations use by a system integrator or other software vendors
How customers are leveraging Centralized Deployment
Several global customers are already using Centralized Deployment today. See how Genetec Inc., an Office 365 customer, is using this service to solve their organizations needs with the Qorus Office 365 add-ins for RFP’s.
“With Office 365 Centralized Deployment we could deploy Qorus easily to our global user base and the process is transparent to users – when they open Microsoft Word or PowerPoint they find the add-in already installed.” – Eric Jacobs, Genetec Inc.
Get started with Centralized Deployment !
Verify compatibility
IT admins can review requirements documentation or run a script to determine if the organization has the correct configuration to use Centralized Deployment
Individuals in the organization can use the deployment compatibility checker add-in to verify supported versions of Office and Exchange.
Q. How do you target add-in user assignments with Centralized Deployment?
A. Centralized Deployment supports users in top-level groups, Office 365 Groups, distribution lists and security groups that are top-level groups supported by Azure Active Directory.
Q. How do I know if my organization is set up for Centralized Deployment?
A. Centralized Deployment requires a recent version of Microsoft Office and OAuth enabled version of Exchange. IT admins can run a quick test to ensure compatibility and determine if their organization has the correct configuration prior to getting started.
Q. What languages and worldwide Office data centers are supported?
A. Today, we have worldwide support for Centralized Deployment for all supported Office languages. We also support the Microsoft Office sovereign datacenters for Germany, with support for Chinese sovereign deployment coming later in the year.
Q. What type of deployment telemetry is available?
A. Telemetry will be available shortly for IT admins to see data about deployments and usage in reports in the Office 365 admin center, and for developers to see their add-in deployments in the Office ISV Seller Dashboard, their developer portal.
Q. Can IT admins and users turn off add-ins?
A. IT admins may turn on or off the add-ins they deploy for all users from the Office 365 admin center. Soon, we will support the ability for users turn off add-ins that are deployed to them, so they are no longer shown on the Office applications ribbon.
Q. How do I deploy Outlook add-ins?
A. Centralized Deployment currently supports Word, Excel and PowerPoint add-ins on Windows, Mac or Office Online. Today, you can deploy Outlook add-ins from the Exchange management pages. This experience will merge with Centralized Deployment shortly.
Welcome to the latest edition of the Modern Service Management for Office 365 blog series! In this article, we review monitoring tools and techniques to manage information security using audit data. These insights and best practices are brought to you by Carroll Moon, Senior Architect for Modern Service Management.
In the Monitoring and Major Incident Management post, we discussed how monitoring can mean many things. In that post, we focused on monitoring for availability and performance. In this post, we will focus on audit and bad-guy-detection.
The most important part of this discussion is the ManagementActivityAPI. That API was announced in April of 2015 here. The MSDN reference is here and the schema is here. For many IT Pros, using the API is something they do not have the current ability (of course, they could learn) or time to focus on. My goal here is to help simplify the discussion so everyone can start to get business benefit from the API.
What should you be looking for?
Before we get into the “how”, we should discuss the “why” and the “what”. The question that most readers will be asking is “why should I care”? The answer to that question is “it comes down to scenarios”. Would it help you with audit and compliance requirements to be able to provide a report for “which admins gave themselves permissions to another user’s mailbox” last month? Would it help you with security monitoring to alert on the condition of “if an account has X failed login attempts in Y minutes”? Would it be helpful to your Service Desk’s goal of becoming more proactive to have a report of all users who got “access denied” for SharePoint files so the Service Desk can go proactively train them?
There are countless scenarios that can be enabled by this data. I encourage you to spend time talking to your compliance, security, audit and Service Desk teams to brainstorm how this data can help them be more successful in reaching their goals. Once you land on a couple of scenarios (the “why” and “what”), then it will be more fun to talk about the “how”.
We have the API, now what?
I have included the links to the API’s reference and schema above, but what does that mean? To use the API, one needs to think of the data flow in steps:
We need to get the data from the API. We would create a job that runs every N minutes using an appropriately permissioned service account to pull the data.
We need to store the data. Usually, this would imply that we have a big-data-type monitoring or reporting solution in place that we will use for this data. If we do not have something already, we likely will want to go through a planning exercise.
Once we have the data in a usable format, we need to quantify the queries against the data for the scenarios that matter to us. Remember, we discussed the scenarios above. For example, “I want to know if an account has X failed logins in Y minutes”.
And once we’ve quantified our scenarios and related queries, we need to expose the data. We will likely want reports and alerts. We will want to tie the alerts to our existing single pane of glass, and we will want to define the subsequent worflows. For those alerts, we are effectively just adding “Major Incident” Scenarios to our list discussed already in this blog post.
Surely, there is an easier way…
There are starter solutions for what I’ve described above. Many 3rd parties have built solutions that pull from the API and start to quantify patterns, reports, and alerts that most enterprise customers will care about. See this announcement for a list of some of the 3rd parties who have done work in this area.
But what about a first-party solution from Microsoft?
There is a feature in Azure called Operations Management Suite (OMS). Within OMS, there is a feature called Log Analytics. Note that as of this writing, the introductory level of Log Analytics is free as described here.
On top of OMS Log Analytics, Microsoft has published a public preview of a solution to do steps 1-4 for our enterprise customers. You can learn more about that solution pack here.
Side Note: I encourage everyone to think of OMS Log Analytics not as a “new tool”, but as a feature in Azure that can be leveraged to enable scenarios. Just like Azure Machine Learning allows you to take advantage of ML capabilities without building your own, proprietary ML platform, OMS Log Analytics allows your business to take advantage of “big-data-monitoring” with minimal overhead. You just turn the feature on, and you pay only as you choose to store more information. It is a great new paradigm.
Wrapping it up
The ManagementActivityAPI provides data that allows customers to be very creative with scenarios for monitoring and reporting
No matter what toolset you use (or even if you do not have any tools), you can download, store, query, report, and alert on the data from the ManagementActivityAPI to enable your scenarios
Many 3rd parties have added solutions on top of their existing products to help everyone get started with these scenarios
Microsoft has a first-party solution (in preview) in Azure’s OMS Log Analytics feature that will help you get started very quickly
I’d love to hear about your business’ scenarios. Let me know how you are using the ManagementActivityAPI to help your business via twitter at @carrollm_itsm
We’re back with another edition of the Modern Service Management for Office 365 blog series! In this article, we review monitoring with a focus on communications from Microsoft related to incident and change management. These insights and best practices are brought to you by Carroll Moon, Senior Architect for Modern Service Management and Chris Carlson, Senior Consultant for Modern Service Management.
Thanks to everyone who is following along with this Modern Service Management for Office 365 series! We hope that it is helpful so far. We wanted to round out the Monitoring and Major Incident Management topic with some real, technical goodness in this blog post. The Office 365 Service Communications API is the focus for this post, and the context for this post may be found here. We will focus on version 1 of the API and version 2 is currently in preview.
In order to integrate the information from the Office 365 Service Communications API with your existing monitoring toolset, there are two main options:
Often though, in large enterprises, the monitoring team may be in a separate organization from the Office 365-focused team. Often their priorities and timelines for such an effort in a 3rd party tool do not align. Also, it is often the case that the monitoring tools team’s skillset is phenomenal when it comes to the tool, but less experience exists in writing scripts with a focus on Office 365 scenarios. All of that can be worked through, but it is often simpler to have the Office 365 focused team(s) focus on the script and the business rules while the monitoring team focuses on the tool. In that case, the following scenario tends to work better:
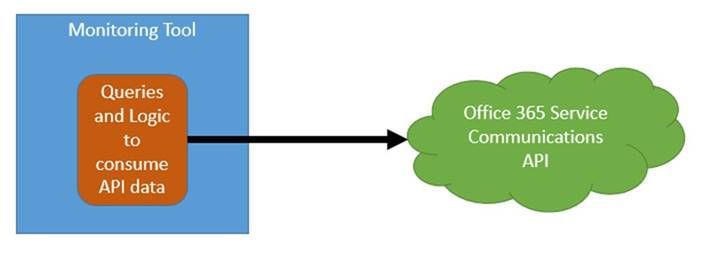
Decouple the queries and logic from the toolset. The script runs from a “watcher node” (which is just a fancy term for a machine that runs the script) owned by the Office 365-focused team, and then the monitoring team simply a) installs an agent on the watcher node b) scrapes the event IDs defined by the Office 365-team and c) builds a few wizard-driven rules within the monitoring tool. This approach also has the benefit of giving the Office 365-focused team some agility because script updates will not require monitoring tool changes unless the event IDs are changing. This approach is also helpful in environments where policy does not allow any administrative access to Office 365 by monitoring-owned service accounts.
Microsoft does not have a preference as to which approach you take. We do want you to consume the communications as defined in the “monitoring scenarios” in this blog post, but how you accomplish that is up to you. For this blog post, however, we will focus on option #2.
The guidance and suggestions outlined below are shared by Chris Carlson. Chris is a consultant and helps organizations simplify their IT Service Management process integration with the Microsoft Cloud after spending time in the Office 365 product group. Chris has created sample code as an example (“B” above). Chris has also defined the rules and event structure that your monitoring team would use to complete their portion of the work (“A” above). The rest of this article is brought to you by Chris Carlson (thank you Chris!!)
Carroll Moon
———-
As Carroll has alluded, my recommended method for monitoring Office 365 is to leverage the Office 365 SCOM Management Pack. But for those Office 365 customer’s that do not already have an investment in System Center and no plans in the near future to deploy it, I don’t believe that should reduce the experience when it comes to monitoring our online services and integrating that monitoring experience into your existing tools and IT workflows. In order to realize Carroll’s decoupled design in section #2 above we will need some sort of client script or code that will call the API and then output the returned data into a format that we can easily ‘scrape’ into our monitoring tool. For the sake of this example, I will focus on how this can be accomplished using some sample code I published a few days ago. This sample code creates a Windows service that queries the Office 365 Service Communications API and writes the returned data into a Windows event log that can easily be integrated into most 3rd party monitoring tools available today. I’ll walk through the very brief installation process for the sample watcher service, run down the post installation configuration items needed to get you setup and then provide details on what events to look for to build monitoring rules. So let’s get started.
Installation
First off we need to download the sample watcher code and identify a host where we want this service to run. For the purpose of today’s write-up I am installing this onto my Windows 10 laptop but there should be no restriction as to where you run this. Of course the usual caveats apply that this is sample code and you should test in a non-production environment…with that disclaimer out of the way, if you are not one to mess with Visual Studio, for whatever reason, and don’t want to compile your own version of the watcher I did include a pre-compiled version of the service installer in the zip file you will find available for download. To locate this installer, simply download the sample solution, extract the zip file to a location on your local drive and navigate to the C#Service Installer folder and there you will find setup.exe.
When running setup.exe may run into Windows Defender trying to protect you with the following warning message:
If this does appear, simply click the More info button I circled above and you’ll be presented with a Run anyway button which will allow you to bypass the defender protection, as shown below.
Once we are passed the Windows Defender warnings, the installation really is straightforward. There are three wizard driven screens that will walk you through the service installation process and as you will see in this sample there is no configuration required during the wizard, simply click Next, Install and Finish, as shown below.
Once the installation wizard has completed, you can verify installation by looking at the list of installed applications via the usual places (Control Panel, Programs, Programs and Features). My Windows 10 machine shows the following entry.
In addition, you can open the services MMC panel (Start->Run->Services.msc) and view the installed service named Microsoft Office 365 Service Health Watcher. The service is installed with a startup type of automatic but left in a stopped state initially. This is because we have some post installation configuration to do prior to spinning it up for the first time. (Yes, I could have extended the install wizard to collect these items, but we’re all busy and this is sample code.) Please read on because the next section will discuss the required configuration items that need to be set and all the other possible values that are available in this sample to modify the monitoring experience.
Service Configuration
So now we have an installed Windows service that will poll the Office 365 Service Communications API for data but we need to tell that service which Office 365 tenant we are interested in monitoring. To do this we need to open the configuration file and enter a few tenant specific values. The service we installed above places files into the C:Program Files (x86)Microsoft Office 365 Service Health Watcher folder and it’s in that location that you will find the file named Microsoft Office 365 Service Health Watcher.exe.config. This is an XML file so you can open and modify it in any of your favorite XML editors, I am using trusty old Notepad for my editing today. When you open the file you will see a few elements listed, similar to the ones below, what we care about however are the attributes of the ConfigSettings element.
There are several attributes here that can change the way this sample operates, I have listed out all attributes and their meanings below in Table 1, but to get started you need only update the values for DomainNames, UserName and Password. Referring back to the sample code download page, DomainNames represents the domain name of the tenant to be monitored, i.e. contoso.com, adventureworks.com, .com. UserName needs to contain a user within that same tenant that has been granted the Service administrator role, for more information on Office 365 user roles please review the Office 365 Admin help page. Password is the final attribute that requires a value and this will be the password for the user you defined in the UserName attribute. As noted on the sample code page, this value is stored in plain text within this configuration file. This sample can certainly be extended with your favorite method of encrypting this value but for the sake of board sample usage I chose not to include that functionality at this time. I do however recommend the account used is one that only has the Service administrator role and you review who has permissions to this file to at least ensure a basic level of protection on these credentials.
Table 1 – Watcher Service Configuration items
Configuration Item
Description
ServiceURL
This is the URL endpoint for the Service Comms API
DomainNames
The domain name of the tenant to be queried for i.e. contoso.com
UserName
The name of a user, defined in the Office 365 tenant, that has ‘Service Administrator’ rights.
Password
The password associated with the above user. See notes about securing this value
PollInterval
This value determines how often, in seconds, the API is polled for new information. The default value is 900 seconds, or 15 minutes.
PastDays
How many days of historical data is retrieved from the API during each poll. The default value is 30 days and it is recommended not to modify this value.
FreshnessThresholdDays
The number of days the locally tracked data in the registry is considered ‘fresh’. This value only applies in case where the API has not been polled for an extended period of time. The sample code will ignore the data in the local registry and update it with new entries from the next API call.
AlertMessageCenterEvents
Can we used to turn off events related to general notifications found in the Message Center. A value of 0 will disable these events and a value of 1 will enable them, the default value is 1.
AlertPlannedMaintenanceEvents
Can we used to turn off events related to Planned Maintenance. A value of 0 will disable these events and a value of 1 will enable them, the default value is 1.
AlertServiceIncidentEvents
Can we used to turn off events related to Service Incident messages. A value of 0 will disable these events and a value of 1 will enable them, the default value is 1.
Once you have defined values for these three required items it’s time to fire up the service and give it a try! Read on for what to expect from this sample watcher and how you can, should you choose, build monitoring rules to integrate into your existing systems.
Using the watcher sample to monitor Office 365
To briefly recap, in the previous sections we have installed a sample watcher service and configured it with our Office 365 tenant specific information so now we are ready to let it connect to the Office 365 Service Communications API for the first time and start monitoring our Office 365 tenant, great! If we go to the services MMC panel (Start->Run->services.msc) we can start the service named Microsoft Office 365 Service Health Watcher, as shown below.
This service will write it’s events to the Application event log on the Windows host it was installed on. So let’s open Event Viewer (Start->Run->eventvwr.msc) and see what data we are getting back. Below is a screen shot of my Application event log filtered to an event source of Microsoft Office 365 Service Health Watcher, that is the source for all the events this sample writes to the Application event log. NOTE: You are certainly welcome to extend the sample and register your own source and event values if you like, sky is the limit on that kind of stuff.
We see above that there is a lot of data coming back from the Service Communications API, so let’s dig into some of these events and see what data this thing is returning…
First we are greeted with a few standard messages, those events with IDs in the 4000 range are related to the watcher process itself, for instance the first two are basic messages that the service has in fact started and it’s starting a polling cycle:
Not terribly interesting but they can be leveraged as a type of heartbeat to ensure monitoring of Office 365 is occurring. For instance, in most monitoring tools you can build a rule that contains logic that will alert when an event is NOT detected within a known period of time, in this case we should be dropping these events every 15 minutes assuming the default polling interval. If we don’t see event ID 4010 then we know we our monitoring is not working for some reason and need to investigate as we could miss important data related to Office 365 service incidents.
Moving on to examine a few more of the events, we see that the next one that was written was an error event with an ID of 1001, for this sample watcher event IDs in the 1000 range denote events related Service Incidents. We can see in the event below that this was an Exchange Online related issue with OWA access that occurred sometime back and has since been resolved.
Service Incidents will progress through a series of state, or ‘status’, changes throughout the lifecycle of that incident so you can use the status field returned in these events to further key alerting to specific workflow states i.e. Service restored, Post-incident report published, etc.
In addition to Service Incident events this watcher sample also drops events related to Planned Maintenance and Message Center event types. The Message Center is the primary change management tool for Office 365 and is used to communicate directly to admins and IT Pros. New feature releases, upcoming changes, and situations requiring action are communicated through the Office 365 Message Center and this API. The example below is a communication that Office 2016 is now recommended and that Office 2013 version of ProPlus will not be available from the portal starting March 1st.
Another example, below, is a communication related to Yammer and how your tenant may be affected.
In many cases these messages, not just service incidents, represent direct action that needs to be taken by someone, whether that individual is within IT or another business unit depends but awareness of the messages needs to be communicated, or ‘alerted’, to the appropriate person or automated workflow. To that end the table below represents a full list of the event types and the event ID that can be dropped by this sample watcher service. In addition I have provided a description of what my intention was when writing the event to the event log and how it might be used to build monitoring related rules.
Table 2 – EventIDs and Descriptions
Event Type
EventID
Purpose
Service Incident
1001
This event indicates a new service incident has been posted for the monitored Office 365 tenant. This should be used to alert that a new service incident has been detected. NOTE: This will event will also be written when the service is started for the first time and an existing service incident is returned from the API. This will also be written when the watcher has been offline longer than the value listed in FreshnessThresholdDays in the XML config file.
Service Incident
1002
This event indicates a status change for a tracked service incident, since the last poll cycle. This should be used to notify that something noteworthy has changed with the service health state. A review of the service incident’s status message should take place to determine what the status change is. For example, if a service incident has changed from an active state to a resolved status.
Service Incident
1003
This event is used simply to inform that we are still seeing data being returned for a tracked service incident, it really is informational in nature.
Planned Maintenance
2001
This event is written when a new Planned Maintenance message has been posted for the tenant. The same conditions as noted for event 1001 apply as to the conditions under which this event would be written.
Planned Maintenance
2002
Like event 1002, this event informs that status has changed, since the last poll cycle, for this planned maintenance event. This event should indicate that a planned maintenance has started, cancelled or been completed.
Planned Maintenance
2003
Like event 1003, this event just notes that we are still seeing data for a tracked planned maintenance event and is informational only.
Message Center
3001
Indicates a new Message Center event with a category of ‘Stay Informed’ was returned by the API.
Message Center
3002
Indicates a new Message Center event with a category of ‘Plan for Change’ was returned by the API.
Message Center
3003
Indicates a new Message Center event with a category of ‘Prevent Or Fix Issues’ was returned by the API.
Health Watcher
4001
Indicates that the watcher service has been started
Health Watcher
4002
Indicates that the watcher service has been stopped
Health Watcher
4003
A connection attempt to the Service Communications API was attempted but was unsuccessful, possibly due to network connectivity or invalid credentials.
Health Watcher
4004
A successful connection to the Service Communications API was made but no event data was returned. A likely reason for this would be attempting to use a credential without enough permissions to retrieve data for the specified tenant.
Health Watcher
4006
Indicates that an unhandled exception was detected in watcher code.
Health Watcher
4008
This event is dropped when a tracking registry key is deleted. This would only occur if there is tracked data in the registry and the watcher enters a ‘first poll’ experience. This would most likely be when the watcher has been offline longer than the value of FreshnessThresholdDays.
Health Watcher
4009
This event is written when the XML configuration file does not contain a value for DomainName, UserName or Password. Typically this would be if the service is started before the XML config file has been updated.
Health Watcher
4010
An event that is written each time the API polling cycle begins i.e. every 15 min by default. This can be used to determine if API polling is still functioning i.e. monitor for the absence of this event within the last N # of minutes.
Health Watcher
4011
An event that is written each time the API polling cycle completes
More information
I am always looking for feedback and am happy to answer any questions. If you have any feedback, comments, questions, concerns or even suggestions on how to improve the sample watcher service feel free to leave comments on this blog post or use the Q & A section on the sample code download site. As Carroll mentioned, we’ll be looking to update this sample in the near future using the V2 API and incorporate the changes coming with that version.
We’re back with another edition of the Modern Service Management for Office 365 blog series! In this article, we review monitoring with a focus on communications from Microsoft related to incident and change management. These insights and best practices are brought to you by Carroll Moon, Senior Architect for Modern Service Management and Chris Carlson, Senior Consultant for Modern Service Management.
Thanks to everyone who is following along with this Modern Service Management for Office 365 series! We hope that it is helpful so far. We wanted to round out the Monitoring and Major Incident Management topic with some real, technical goodness in this blog post. The Office 365 Service Communications API is the focus for this post, and the context for this post may be found here. We will focus on version 1 of the API and version 2 is currently in preview.
In order to integrate the information from the Office 365 Service Communications API with your existing monitoring toolset, there are two main options:
Often though, in large enterprises, the monitoring team may be in a separate organization from the Office 365-focused team. Often their priorities and timelines for such an effort in a 3rd party tool do not align. Also, it is often the case that the monitoring tools team’s skillset is phenomenal when it comes to the tool, but less experience exists in writing scripts with a focus on Office 365 scenarios. All of that can be worked through, but it is often simpler to have the Office 365 focused team(s) focus on the script and the business rules while the monitoring team focuses on the tool. In that case, the following scenario tends to work better:
Decouple the queries and logic from the toolset. The script runs from a “watcher node” (which is just a fancy term for a machine that runs the script) owned by the Office 365-focused team, and then the monitoring team simply a) installs an agent on the watcher node b) scrapes the event IDs defined by the Office 365-team and c) builds a few wizard-driven rules within the monitoring tool. This approach also has the benefit of giving the Office 365-focused team some agility because script updates will not require monitoring tool changes unless the event IDs are changing. This approach is also helpful in environments where policy does not allow any administrative access to Office 365 by monitoring-owned service accounts.
Microsoft does not have a preference as to which approach you take. We do want you to consume the communications as defined in the “monitoring scenarios” in this blog post, but how you accomplish that is up to you. For this blog post, however, we will focus on option #2.
The guidance and suggestions outlined below are shared by Chris Carlson. Chris is a consultant and helps organizations simplify their IT Service Management process integration with the Microsoft Cloud after spending time in the Office 365 product group. Chris has created sample code as an example (“B” above). Chris has also defined the rules and event structure that your monitoring team would use to complete their portion of the work (“A” above). The rest of this article is brought to you by Chris Carlson (thank you Chris!!)
Carroll Moon
———-
As Carroll has alluded, my recommended method for monitoring Office 365 is to leverage the Office 365 SCOM Management Pack. But for those Office 365 customer’s that do not already have an investment in System Center and no plans in the near future to deploy it, I don’t believe that should reduce the experience when it comes to monitoring our online services and integrating that monitoring experience into your existing tools and IT workflows. In order to realize Carroll’s decoupled design in section #2 above we will need some sort of client script or code that will call the API and then output the returned data into a format that we can easily ‘scrape’ into our monitoring tool. For the sake of this example, I will focus on how this can be accomplished using some sample code I published a few days ago. This sample code creates a Windows service that queries the Office 365 Service Communications API and writes the returned data into a Windows event log that can easily be integrated into most 3rd party monitoring tools available today. I’ll walk through the very brief installation process for the sample watcher service, run down the post installation configuration items needed to get you setup and then provide details on what events to look for to build monitoring rules. So let’s get started.
Installation
First off we need to download the sample watcher code and identify a host where we want this service to run. For the purpose of today’s write-up I am installing this onto my Windows 10 laptop but there should be no restriction as to where you run this. Of course the usual caveats apply that this is sample code and you should test in a non-production environment…with that disclaimer out of the way, if you are not one to mess with Visual Studio, for whatever reason, and don’t want to compile your own version of the watcher I did include a pre-compiled version of the service installer in the zip file you will find available for download. To locate this installer, simply download the sample solution, extract the zip file to a location on your local drive and navigate to the C#Service Installer folder and there you will find setup.exe.
When running setup.exe may run into Windows Defender trying to protect you with the following warning message:
If this does appear, simply click the More info button I circled above and you’ll be presented with a Run anyway button which will allow you to bypass the defender protection, as shown below.
Once we are passed the Windows Defender warnings, the installation really is straightforward. There are three wizard driven screens that will walk you through the service installation process and as you will see in this sample there is no configuration required during the wizard, simply click Next, Install and Finish, as shown below.
Once the installation wizard has completed, you can verify installation by looking at the list of installed applications via the usual places (Control Panel, Programs, Programs and Features). My Windows 10 machine shows the following entry.
In addition, you can open the services MMC panel (Start->Run->Services.msc) and view the installed service named Microsoft Office 365 Service Health Watcher. The service is installed with a startup type of automatic but left in a stopped state initially. This is because we have some post installation configuration to do prior to spinning it up for the first time. (Yes, I could have extended the install wizard to collect these items, but we’re all busy and this is sample code.) Please read on because the next section will discuss the required configuration items that need to be set and all the other possible values that are available in this sample to modify the monitoring experience.
Service Configuration
So now we have an installed Windows service that will poll the Office 365 Service Communications API for data but we need to tell that service which Office 365 tenant we are interested in monitoring. To do this we need to open the configuration file and enter a few tenant specific values. The service we installed above places files into the C:Program Files (x86)Microsoft Office 365 Service Health Watcher folder and it’s in that location that you will find the file named Microsoft Office 365 Service Health Watcher.exe.config. This is an XML file so you can open and modify it in any of your favorite XML editors, I am using trusty old Notepad for my editing today. When you open the file you will see a few elements listed, similar to the ones below, what we care about however are the attributes of the ConfigSettings element.
There are several attributes here that can change the way this sample operates, I have listed out all attributes and their meanings below in Table 1, but to get started you need only update the values for DomainNames, UserName and Password. Referring back to the sample code download page, DomainNames represents the domain name of the tenant to be monitored, i.e. contoso.com, adventureworks.com, .com. UserName needs to contain a user within that same tenant that has been granted the Service administrator role, for more information on Office 365 user roles please review the Office 365 Admin help page. Password is the final attribute that requires a value and this will be the password for the user you defined in the UserName attribute. As noted on the sample code page, this value is stored in plain text within this configuration file. This sample can certainly be extended with your favorite method of encrypting this value but for the sake of board sample usage I chose not to include that functionality at this time. I do however recommend the account used is one that only has the Service administrator role and you review who has permissions to this file to at least ensure a basic level of protection on these credentials.
Table 1 – Watcher Service Configuration items
Configuration Item
Description
ServiceURL
This is the URL endpoint for the Service Comms API
DomainNames
The domain name of the tenant to be queried for i.e. contoso.com
UserName
The name of a user, defined in the Office 365 tenant, that has ‘Service Administrator’ rights.
Password
The password associated with the above user. See notes about securing this value
PollInterval
This value determines how often, in seconds, the API is polled for new information. The default value is 900 seconds, or 15 minutes.
PastDays
How many days of historical data is retrieved from the API during each poll. The default value is 30 days and it is recommended not to modify this value.
FreshnessThresholdDays
The number of days the locally tracked data in the registry is considered ‘fresh’. This value only applies in case where the API has not been polled for an extended period of time. The sample code will ignore the data in the local registry and update it with new entries from the next API call.
AlertMessageCenterEvents
Can we used to turn off events related to general notifications found in the Message Center. A value of 0 will disable these events and a value of 1 will enable them, the default value is 1.
AlertPlannedMaintenanceEvents
Can we used to turn off events related to Planned Maintenance. A value of 0 will disable these events and a value of 1 will enable them, the default value is 1.
AlertServiceIncidentEvents
Can we used to turn off events related to Service Incident messages. A value of 0 will disable these events and a value of 1 will enable them, the default value is 1.
Once you have defined values for these three required items it’s time to fire up the service and give it a try! Read on for what to expect from this sample watcher and how you can, should you choose, build monitoring rules to integrate into your existing systems.
Using the watcher sample to monitor Office 365
To briefly recap, in the previous sections we have installed a sample watcher service and configured it with our Office 365 tenant specific information so now we are ready to let it connect to the Office 365 Service Communications API for the first time and start monitoring our Office 365 tenant, great! If we go to the services MMC panel (Start->Run->services.msc) we can start the service named Microsoft Office 365 Service Health Watcher, as shown below.
This service will write it’s events to the Application event log on the Windows host it was installed on. So let’s open Event Viewer (Start->Run->eventvwr.msc) and see what data we are getting back. Below is a screen shot of my Application event log filtered to an event source of Microsoft Office 365 Service Health Watcher, that is the source for all the events this sample writes to the Application event log. NOTE: You are certainly welcome to extend the sample and register your own source and event values if you like, sky is the limit on that kind of stuff.
We see above that there is a lot of data coming back from the Service Communications API, so let’s dig into some of these events and see what data this thing is returning…
First we are greeted with a few standard messages, those events with IDs in the 4000 range are related to the watcher process itself, for instance the first two are basic messages that the service has in fact started and it’s starting a polling cycle:
Not terribly interesting but they can be leveraged as a type of heartbeat to ensure monitoring of Office 365 is occurring. For instance, in most monitoring tools you can build a rule that contains logic that will alert when an event is NOT detected within a known period of time, in this case we should be dropping these events every 15 minutes assuming the default polling interval. If we don’t see event ID 4010 then we know we our monitoring is not working for some reason and need to investigate as we could miss important data related to Office 365 service incidents.
Moving on to examine a few more of the events, we see that the next one that was written was an error event with an ID of 1001, for this sample watcher event IDs in the 1000 range denote events related Service Incidents. We can see in the event below that this was an Exchange Online related issue with OWA access that occurred sometime back and has since been resolved.
Service Incidents will progress through a series of state, or ‘status’, changes throughout the lifecycle of that incident so you can use the status field returned in these events to further key alerting to specific workflow states i.e. Service restored, Post-incident report published, etc.
In addition to Service Incident events this watcher sample also drops events related to Planned Maintenance and Message Center event types. The Message Center is the primary change management tool for Office 365 and is used to communicate directly to admins and IT Pros. New feature releases, upcoming changes, and situations requiring action are communicated through the Office 365 Message Center and this API. The example below is a communication that Office 2016 is now recommended and that Office 2013 version of ProPlus will not be available from the portal starting March 1st.
Another example, below, is a communication related to Yammer and how your tenant may be affected.
In many cases these messages, not just service incidents, represent direct action that needs to be taken by someone, whether that individual is within IT or another business unit depends but awareness of the messages needs to be communicated, or ‘alerted’, to the appropriate person or automated workflow. To that end the table below represents a full list of the event types and the event ID that can be dropped by this sample watcher service. In addition I have provided a description of what my intention was when writing the event to the event log and how it might be used to build monitoring related rules.
Table 2 – EventIDs and Descriptions
Event Type
EventID
Purpose
Service Incident
1001
This event indicates a new service incident has been posted for the monitored Office 365 tenant. This should be used to alert that a new service incident has been detected. NOTE: This will event will also be written when the service is started for the first time and an existing service incident is returned from the API. This will also be written when the watcher has been offline longer than the value listed in FreshnessThresholdDays in the XML config file.
Service Incident
1002
This event indicates a status change for a tracked service incident, since the last poll cycle. This should be used to notify that something noteworthy has changed with the service health state. A review of the service incident’s status message should take place to determine what the status change is. For example, if a service incident has changed from an active state to a resolved status.
Service Incident
1003
This event is used simply to inform that we are still seeing data being returned for a tracked service incident, it really is informational in nature.
Planned Maintenance
2001
This event is written when a new Planned Maintenance message has been posted for the tenant. The same conditions as noted for event 1001 apply as to the conditions under which this event would be written.
Planned Maintenance
2002
Like event 1002, this event informs that status has changed, since the last poll cycle, for this planned maintenance event. This event should indicate that a planned maintenance has started, cancelled or been completed.
Planned Maintenance
2003
Like event 1003, this event just notes that we are still seeing data for a tracked planned maintenance event and is informational only.
Message Center
3001
Indicates a new Message Center event with a category of ‘Stay Informed’ was returned by the API.
Message Center
3002
Indicates a new Message Center event with a category of ‘Plan for Change’ was returned by the API.
Message Center
3003
Indicates a new Message Center event with a category of ‘Prevent Or Fix Issues’ was returned by the API.
Health Watcher
4001
Indicates that the watcher service has been started
Health Watcher
4002
Indicates that the watcher service has been stopped
Health Watcher
4003
A connection attempt to the Service Communications API was attempted but was unsuccessful, possibly due to network connectivity or invalid credentials.
Health Watcher
4004
A successful connection to the Service Communications API was made but no event data was returned. A likely reason for this would be attempting to use a credential without enough permissions to retrieve data for the specified tenant.
Health Watcher
4006
Indicates that an unhandled exception was detected in watcher code.
Health Watcher
4008
This event is dropped when a tracking registry key is deleted. This would only occur if there is tracked data in the registry and the watcher enters a ‘first poll’ experience. This would most likely be when the watcher has been offline longer than the value of FreshnessThresholdDays.
Health Watcher
4009
This event is written when the XML configuration file does not contain a value for DomainName, UserName or Password. Typically this would be if the service is started before the XML config file has been updated.
Health Watcher
4010
An event that is written each time the API polling cycle begins i.e. every 15 min by default. This can be used to determine if API polling is still functioning i.e. monitor for the absence of this event within the last N # of minutes.
Health Watcher
4011
An event that is written each time the API polling cycle completes
More information
I am always looking for feedback and am happy to answer any questions. If you have any feedback, comments, questions, concerns or even suggestions on how to improve the sample watcher service feel free to leave comments on this blog post or use the Q & A section on the sample code download site. As Carroll mentioned, we’ll be looking to update this sample in the near future using the V2 API and incorporate the changes coming with that version.
We’re back with another edition of the Modern Service Management for Office 365 blog series! In this article, we review the function of IT with Office 365 and evolution of IT Pro roles for the cloud. These insights and best practices are brought to you by Carroll Moon, Senior Architect for Modern Service Management.
In this installment of the blog series, we will dive into the “Business Consumption and Productivity” topic. The whole point of the “Business Consumption and Productivity” category is to focus on the higher-order business projects for whatever business you are in. If you are in the cookie-making business, then the focus should be on making cookies. The opportunity is to use Office 365 to drive productivity for your cookie-making users, to increase market share of your cookie business, or to reduce costs of producing or selling your cookies. This category is about the business rather than about IT. We all want to evolve IT to be more about driving those business-improvement projects. However, in order for IT to help drive those programs with (and for) the business, we need to make sure that the IT Pros and the IT organization are optimized (and are excited) to drive the business improvements. We all need to look at the opportunities to do new things by using the features and the data provided by the Office 365 service to drive business value rather than looking at what we will no longer do or what we will do differently. I always say that none of us got into IT so we could manually patch servers on the weekends, and none of us dreamed about sitting on outage bridges in the middle of the night. On the contrary, most of us got into IT so we could drive cool innovation and cool outcomes with innovative use of technology. I like the idea of using Office 365 as a conduit to get back to our dreams of changing the business/world for the better using technology.
For IT Pros
If you are an IT Pro in an organization who is moving to Office 365 (or to the cloud, or to a devops approach), I would encourage you to figure out where you want to focus. In my discussions with many customers, I encounter IT Pros who are concerned about what the cloud and devops will mean to their careers. My response is always one of excitement. There is opportunity! The following bullets outline just a few of the opportunities that are in front of us all:
Business-Value Programs. If I were a member of the project team for Office 365 at one of our customers, I would not be able to contain my excitement for driving change in the business. I would focus on one or more scenarios; for example, driving down employee travel costs by using Skype for Business. Such a project would save the company money, but it would also positively impact people’s lives by letting them spend more time at home and less time in hotels for work, so such a scenario would be very fulfilling. I would focus on one or more departments or business units who really want to drive change. Perhaps it would be the sales department because they have the highest travel budget and the highest rate of employee turnover due to burnout in this imaginary example. I would use data provided by the Office 365 user reports and combine it with existing business data on Travel Cost/user/month. I would make a direct impact on the bottom line with my project. I would be able to prove that as Skype for Business use in the Sales Department went up, Travel Costs/user/month went down. That would be real, measurable value, and that would be fun! There are countless scenarios to focus on. By driving the scenarios, I would prove significant business impact, and I would create a new niche for myself. What a wonderful change that would be for many IT Pros from installing servers and getting paged in the middle of the night to driving measurable business impact and improving people’s lives.
Evolution of Operations. In most organizations, the move to cloud (whether public or private), the move towards a devops culture, the move towards application modernization, and the growth of shadow-IT will continue to drive new requirements for how Operations provides services to the business and to the application development and engineering teams. As an operations guy, that is very exciting to me. Having the opportunity to define (or at least contribute to) how we will create or evolve our operational services is very appealing. In fact, that is a transformation that I got to help lead at Microsoft in the Office 365 Product Group over the years, and it was very fulfilling. For example, how can the operations team evolve from viewing monitoring as a collection of tools to viewing monitoring as a service that is provided to business and appdev teams? That is a very exciting prospect, and it is an area that will be more and more important to every enterprise over the next N years. The changes are inevitable, so we may as well be excited and drive the changes. We must skate to where the [hockey] puck is going to be rather than where it is right now. See this blog series and this webinar for more on the monitoring-as-a-service example.
Operations Engineering. In support of the evolution of operations topic covered in the previous bullet, there will be numerous projects, services and opportunities where technical prowess is required. In fact, the technical prowess required to deliver on such requirements likely are beyond what we see in most existing operations organizations. Historically, operations is operations and engineering is engineering and the two do not intertwine. In the modern world, operations must be a series of engineering services, so ops really becomes an engineering discussion. Using our monitoring-as-a-service example, there will be a need to have someone architect, design, deploy, and run the new service monitoring service as described in this blog series.
Operations Programs. In further support of the evolution of operations†topic, there will be the need for program management. That’s great news because there will be some IT Pros who do not want to go down the deep bits and bytes route. For example, who is program managing the creation and implementation of the new service monitoring service described this blog series? Who is interfacing with the various business units who have brought in SaaS solutions outside of IT’s purview (shadow IT) to convince them that it is the business best interest to onboard onto IT’s service monitoring service? Who is doing that same interaction with the application development teams who are moving to a devops approach? Who is managing those groups expectations and satisfaction once they onboard to the service monitoring service? Answer: Operations Program Manager(s) need to step up to do that.
Modern Service Desk. Historically, Service Desks have been about “taking lots of calls†and resolving them quickly. The modern service desk must be about enabling users to be more productive. That means that we need to work with engineering teams to be about eliminating calls altogether and when we cannot eliminate an issue, push the resolution to the end-user instead of taking the call at the service desk. The goals should be to help the users be more productive. And that means that we also need to assign the modern service desk the goal of “go seek users to help them be more productive. As discussed in the Monitoring: Audit and Bad-Guy-Detection blog post, wouldn’t it be great if the service desk used the data provided by the service to find users who are having the most authentication failures so they could proactively go train the users? That is just one example, but such a service would delight the user. Such a service would help the business because the user would be more productive. And such a change of pace from reactive to proactive would be a welcome change for most of us working on the service desk. One of my peers, John Clark, just published a two-part series on the topic of Modern Service Desk: Part 1 and Part 2.
Status Quo. Some people do not want to evolve at all, and that should be ok. If you think about it, most enterprises have thousands of applications in their IT Portfolios. Email is just one example. So, if the enterprise moves Email to the cloud, that leaves thousands of other applications that have not yet moved. Also, in most enterprises, there are new on-premise components (e.g. Directory Synchronization) introduced as the cloud comes into the picture; someone has to manage those new components. And, of course, there are often hybrid components (e.g. hybrid smtp mailflow) in the end-to-end delivery chain at least during migrations. And if all else fails, there are other enterprises who are not evolving with cloud and devops as quickly. There are always options.
The bullet list above is not exhaustive for Office 365. The bullets are here as examples only. My hope is that the bullets provide food for thought and excitement. The list expands rapidly as we start to discuss Infrastructure-as-a-Service and Platform-as-a-Service. There is vast opportunity for all of us to truly follow our passions and to chase our dreams. When automobiles were invented, of course some horse and buggy drivers were not excited. I have to assume, however, that some horse enthusiasts were very excited for the automobiles too. For those who were excited to change and evolve, there was opportunity for them with automobiles. For those who wanted to stay with the status quo and keep driving horse-drawn-buggies, they found a way to do that. Even today in 2017, there are horse-drawn-carriage rides in Central Park in New York City (and in many other cities). So, there is always opportunity.
For IT Management
In the ~13 years that I have focused on cloud services at Microsoft since our very first customer for what is now called Office 365 the question that I have been asked the most is “how do I monitor it? The second most frequent question comes from senior IT managers: How do I need to change my IT organization to support Office 365? And a close third most frequent question is from IT Pros and front-line IT managers: How will my role change as we move to Office 365?
Simplicity is a requirement. As you continue on this journey with us in this blog series, I encourage you to push yourself to keep it simple from the service management perspective. Change as little as possible. For example, if you can monitor and integrate with your existing monitoring toolset, do so. We will continue to simplify the scenarios for you to ease that integration. From a process perspective, there is no need to invent something new. For example, you already have a great Major Incident process you have a business and your business is running, so that implies that you are able to handle Major Incidents already. For Office 365, you will want to quantify and plan for the specific Major Incident scenarios that you may encounter. You will want to integrate those scenarios into your existing workflows with joined data from your monitoring streams and the information from the Office 365 APIs. We have covered those examples already in the blog series, so the simplistic approach should be more evident at this point.
From an IT Pro Role and Accountability perspective, it is important to be intentional and specific about how each role will evolve and how the specific accountabilities will evolve in support of Office 365. For example, how should the “Monitoring role change for Email? And how will you measure the role to ensure that the desired behaviors and outcomes are achieved?
What about the IT Organization?
Most of the time, when I get the IT organization question, customers are asking about whether they should reorganize. My answer is always the following: there are three keys to maximizing your outcomes with this cloud paradigm shift:
Assign granular accountabilities…make people accountable, not teams. For example, if we miss an outage with monitoring, senior management should have a single individual who is accountable for that service or feature being adequately covered with monitoring.
Ensure metrics for each accountability…#1 will not do any good if you cannot measure the accountability, so you need metrics. Most of the time, the metrics that you need for this topic can easily be gathered during your existing internal Major Problem Review process.
Hold [at least] monthly Rhythm of the Business meetings with senior management to review the metrics. At Microsoft, we call these meetings Monthly Service Reviews (MSRs). In these meetings, the accountable individuals should represent their achievement (or lack of achievement) of their targets so that senior management can a) make decisions and b) remove blockers. The goal is to enable the decisions to be made at the senior levels without micro-management.
I tell customers that if they get those three things right, the organizational chart becomes about organizing their talent (the accountable people) into the right groups. If one gets those three bullets right, the org chart does not matter as much. However, no matter how one changes the IT Organizational chart, if one gets those three bullets wrong, the outcomes will not be as optimized as we want them to be. So, my guidance is to always to start with these three bullets rather than the org chart. The combination of these three bullets will drive the right outcomes. The right outcomes sometimes drive an organizational chart adjustment, but in most cases, organizational shifts are not required.
Think of it this way, if you move a handful of workloads to the cloud, the majority of your IT portfolio will still be managed as business-as-usual, so a major organizational shift just for the cloud likely will not make sense. If I have 100 apps in my IT portfolio and I move 3 apps to the cloud, then would I re-organize around the 3 apps? Or would I keep my organization intact for the 97 apps and adapt only where I must adapt for the 3 cloud apps?
The IT Organization is about the sum of the IT Pros
From a people perspective, the importance of being intentional and communicative cannot be overstated. Senior management should quantify the vision for the IT organization and articulate how Office 365 fits into that vision. It is important to remember that IT Pros are real people with real families and lives outside of work. Many IT Pros worry that the cloud means that they do not have a job in the future. That, of course, is not true. Just as the centralization of the electrical grid did not eliminate the need for electricians, the centralization of the business productivity grid into the cloud does not eliminate the need for the IT Pro. But just as the role of an electrician evolved as the generation of power moved from the on-premise-water-wheel to the utility grid, the role of IT Pro will evolve as business productivity services move to the cloud. The electrician’s role evolved to be more focused on the business-use of the electrical grid. So too will the IT Pro’s role evolve to support the business value realization of the business productivity services. We intend to help with that journey in future blog posts focused on the Consumption and Productivity category.
As senior management plans through the cloud, we recommend that they dig into at least the following role groupings to plan how each will evolve with respect to Office 365 workloads:
Engineering / Tier 3 / Workload or Service Owners…will we still support servers, or will we focus on tenant management and business improvement projects?
Service Desk Tiers and Service Desk Managers…will we support end-users in the same way? With the same documentation? Will our metrics stay the same, or should they evolve?
Major Incident Managers…will we still run bridges for the Office 365 workloads? How will those bridges be initiated? Will our team’s metrics evolve? Given that many of the MSR metrics come from our Major Problem Reviews, is our team’s importance increasing?
Monitoring Engineers and Monitoring Managers…will we accountable for whether we miss something with monitoring for Office 365 workloads? Or perhaps do we support the monitoring service with the Tier 3 engineers being accountable for the rule sets? Should we focus on building a Service Monitoring Service?
Change and Release Managers…how are we going to absorb the evergreen changes and the pace-of-change from Microsoft and still achieve the required outcomes of our Change and Release Management processes?
As you spend time in the Monitoring and Major Incident Management content in this blog series, I encourage you to think through how implementation of the content may change things for the IT Pros using that example. If you implement the monitoring recommendations, will it be simply business-as-usual for your monitoring team? What about the Tier 3 workload team? Or, perhaps is it a shift in how things are done? Perhaps for your on-premise world, the monitoring team owns the monitoring tool and the installed Exchange monitoring management packs. Perhaps in practice, when there is an outage on-premise, the Service Desk recognizes the outage based on call patterns, and then they initiate an incident bridge. Perhaps once the bridge is underway, someone then opens the monitoring tool to look for a possible root cause of the outage. Will that same approach continue in the cloud for Exchange Online, or should we look to evolve that? Perhaps in the cloud we should have the Tier 3 workload team be accountable for missed by monitoring for any end-to-end impact for Exchange regardless of where root cause lies. Perhaps we should have the monitoring team be accountable for the monitoring service with metrics like we describe here. And perhaps we should review both the Exchange monitoring metrics and the Monitoring Service metrics (and any metric-misses) every month in a Monthly Service Review (MSR) with the IT executive team as covered in #3 above. What I describe here is usually a pretty big, yet desirable, culture shift for most IT teams.
Some customers want hands-on assistance
As I mentioned, I get these questions often. Some customers want Microsoft to help guide them on the IT Pro and organizational front. In response to customer requests, my peers and I have created a 3-day, on-site course for IT Executives and IT Management to help them plan for the people side of the change. The workshop focuses on the scenarios, personas and metrics for the evolution discussed in this blog post. The workshop also helps develop employee communications and resistance management plans. The workshop is part of the Adoption and Change Management Services from Microsoft. Ask your Technical Account Manager about the “Managing Change for IT Pros: Office 365†workshop, or find me onTwitter @carrollm_itsm.
Looking ahead
My goal with this blog post is to get everyone thinking. I hope that the commentary was helpful. We’ll jump back into the scenarios in the next post which will focus on Evergreen Management.
We’re back with another edition of the Modern Service Management for Office 365 blog series! In this article, we review the function of IT with Office 365 and evolution of IT Pro roles for the cloud. These insights and best practices are brought to you by Carroll Moon, Senior Architect for Modern Service Management.
In this installment of the blog series, we will dive into the “Business Consumption and Productivity” topic. The whole point of the “Business Consumption and Productivity” category is to focus on the higher-order business projects for whatever business you are in. If you are in the cookie-making business, then the focus should be on making cookies. The opportunity is to use Office 365 to drive productivity for your cookie-making users, to increase market share of your cookie business, or to reduce costs of producing or selling your cookies. This category is about the business rather than about IT. We all want to evolve IT to be more about driving those business-improvement projects. However, in order for IT to help drive those programs with (and for) the business, we need to make sure that the IT Pros and the IT organization are optimized (and are excited) to drive the business improvements. We all need to look at the opportunities to do new things by using the features and the data provided by the Office 365 service to drive business value rather than looking at what we will no longer do or what we will do differently. I always say that none of us got into IT so we could manually patch servers on the weekends, and none of us dreamed about sitting on outage bridges in the middle of the night. On the contrary, most of us got into IT so we could drive cool innovation and cool outcomes with innovative use of technology. I like the idea of using Office 365 as a conduit to get back to our dreams of changing the business/world for the better using technology.
For IT Pros
If you are an IT Pro in an organization who is moving to Office 365 (or to the cloud, or to a devops approach), I would encourage you to figure out where you want to focus. In my discussions with many customers, I encounter IT Pros who are concerned about what the cloud and devops will mean to their careers. My response is always one of excitement. There is opportunity! The following bullets outline just a few of the opportunities that are in front of us all:
Business-Value Programs. If I were a member of the project team for Office 365 at one of our customers, I would not be able to contain my excitement for driving change in the business. I would focus on one or more scenarios; for example, driving down employee travel costs by using Skype for Business. Such a project would save the company money, but it would also positively impact people’s lives by letting them spend more time at home and less time in hotels for work, so such a scenario would be very fulfilling. I would focus on one or more departments or business units who really want to drive change. Perhaps it would be the sales department because they have the highest travel budget and the highest rate of employee turnover due to burnout in this imaginary example. I would use data provided by the Office 365 user reports and combine it with existing business data on Travel Cost/user/month. I would make a direct impact on the bottom line with my project. I would be able to prove that as Skype for Business use in the Sales Department went up, Travel Costs/user/month went down. That would be real, measurable value, and that would be fun! There are countless scenarios to focus on. By driving the scenarios, I would prove significant business impact, and I would create a new niche for myself. What a wonderful change that would be for many IT Pros from installing servers and getting paged in the middle of the night to driving measurable business impact and improving people’s lives.
Evolution of Operations. In most organizations, the move to cloud (whether public or private), the move towards a devops culture, the move towards application modernization, and the growth of shadow-IT will continue to drive new requirements for how Operations provides services to the business and to the application development and engineering teams. As an operations guy, that is very exciting to me. Having the opportunity to define (or at least contribute to) how we will create or evolve our operational services is very appealing. In fact, that is a transformation that I got to help lead at Microsoft in the Office 365 Product Group over the years, and it was very fulfilling. For example, how can the operations team evolve from viewing monitoring as a collection of tools to viewing monitoring as a service that is provided to business and appdev teams? That is a very exciting prospect, and it is an area that will be more and more important to every enterprise over the next N years. The changes are inevitable, so we may as well be excited and drive the changes. We must skate to where the [hockey] puck is going to be rather than where it is right now. See this blog series and this webinar for more on the monitoring-as-a-service example.
Operations Engineering. In support of the evolution of operations topic covered in the previous bullet, there will be numerous projects, services and opportunities where technical prowess is required. In fact, the technical prowess required to deliver on such requirements likely are beyond what we see in most existing operations organizations. Historically, operations is operations and engineering is engineering and the two do not intertwine. In the modern world, operations must be a series of engineering services, so ops really becomes an engineering discussion. Using our monitoring-as-a-service example, there will be a need to have someone architect, design, deploy, and run the new service monitoring service as described in this blog series.
Operations Programs. In further support of the evolution of operations†topic, there will be the need for program management. That’s great news because there will be some IT Pros who do not want to go down the deep bits and bytes route. For example, who is program managing the creation and implementation of the new service monitoring service described this blog series? Who is interfacing with the various business units who have brought in SaaS solutions outside of IT’s purview (shadow IT) to convince them that it is the business best interest to onboard onto IT’s service monitoring service? Who is doing that same interaction with the application development teams who are moving to a devops approach? Who is managing those groups expectations and satisfaction once they onboard to the service monitoring service? Answer: Operations Program Manager(s) need to step up to do that.
Modern Service Desk. Historically, Service Desks have been about “taking lots of calls†and resolving them quickly. The modern service desk must be about enabling users to be more productive. That means that we need to work with engineering teams to be about eliminating calls altogether and when we cannot eliminate an issue, push the resolution to the end-user instead of taking the call at the service desk. The goals should be to help the users be more productive. And that means that we also need to assign the modern service desk the goal of “go seek users to help them be more productive. As discussed in the Monitoring: Audit and Bad-Guy-Detection blog post, wouldn’t it be great if the service desk used the data provided by the service to find users who are having the most authentication failures so they could proactively go train the users? That is just one example, but such a service would delight the user. Such a service would help the business because the user would be more productive. And such a change of pace from reactive to proactive would be a welcome change for most of us working on the service desk. One of my peers, John Clark, just published a two-part series on the topic of Modern Service Desk: Part 1 and Part 2.
Status Quo. Some people do not want to evolve at all, and that should be ok. If you think about it, most enterprises have thousands of applications in their IT Portfolios. Email is just one example. So, if the enterprise moves Email to the cloud, that leaves thousands of other applications that have not yet moved. Also, in most enterprises, there are new on-premise components (e.g. Directory Synchronization) introduced as the cloud comes into the picture; someone has to manage those new components. And, of course, there are often hybrid components (e.g. hybrid smtp mailflow) in the end-to-end delivery chain at least during migrations. And if all else fails, there are other enterprises who are not evolving with cloud and devops as quickly. There are always options.
The bullet list above is not exhaustive for Office 365. The bullets are here as examples only. My hope is that the bullets provide food for thought and excitement. The list expands rapidly as we start to discuss Infrastructure-as-a-Service and Platform-as-a-Service. There is vast opportunity for all of us to truly follow our passions and to chase our dreams. When automobiles were invented, of course some horse and buggy drivers were not excited. I have to assume, however, that some horse enthusiasts were very excited for the automobiles too. For those who were excited to change and evolve, there was opportunity for them with automobiles. For those who wanted to stay with the status quo and keep driving horse-drawn-buggies, they found a way to do that. Even today in 2017, there are horse-drawn-carriage rides in Central Park in New York City (and in many other cities). So, there is always opportunity.
For IT Management
In the ~13 years that I have focused on cloud services at Microsoft since our very first customer for what is now called Office 365 the question that I have been asked the most is “how do I monitor it? The second most frequent question comes from senior IT managers: How do I need to change my IT organization to support Office 365? And a close third most frequent question is from IT Pros and front-line IT managers: How will my role change as we move to Office 365?
Simplicity is a requirement. As you continue on this journey with us in this blog series, I encourage you to push yourself to keep it simple from the service management perspective. Change as little as possible. For example, if you can monitor and integrate with your existing monitoring toolset, do so. We will continue to simplify the scenarios for you to ease that integration. From a process perspective, there is no need to invent something new. For example, you already have a great Major Incident process you have a business and your business is running, so that implies that you are able to handle Major Incidents already. For Office 365, you will want to quantify and plan for the specific Major Incident scenarios that you may encounter. You will want to integrate those scenarios into your existing workflows with joined data from your monitoring streams and the information from the Office 365 APIs. We have covered those examples already in the blog series, so the simplistic approach should be more evident at this point.
From an IT Pro Role and Accountability perspective, it is important to be intentional and specific about how each role will evolve and how the specific accountabilities will evolve in support of Office 365. For example, how should the “Monitoring role change for Email? And how will you measure the role to ensure that the desired behaviors and outcomes are achieved?
What about the IT Organization?
Most of the time, when I get the IT organization question, customers are asking about whether they should reorganize. My answer is always the following: there are three keys to maximizing your outcomes with this cloud paradigm shift:
Assign granular accountabilities…make people accountable, not teams. For example, if we miss an outage with monitoring, senior management should have a single individual who is accountable for that service or feature being adequately covered with monitoring.
Ensure metrics for each accountability…#1 will not do any good if you cannot measure the accountability, so you need metrics. Most of the time, the metrics that you need for this topic can easily be gathered during your existing internal Major Problem Review process.
Hold [at least] monthly Rhythm of the Business meetings with senior management to review the metrics. At Microsoft, we call these meetings Monthly Service Reviews (MSRs). In these meetings, the accountable individuals should represent their achievement (or lack of achievement) of their targets so that senior management can a) make decisions and b) remove blockers. The goal is to enable the decisions to be made at the senior levels without micro-management.
I tell customers that if they get those three things right, the organizational chart becomes about organizing their talent (the accountable people) into the right groups. If one gets those three bullets right, the org chart does not matter as much. However, no matter how one changes the IT Organizational chart, if one gets those three bullets wrong, the outcomes will not be as optimized as we want them to be. So, my guidance is to always to start with these three bullets rather than the org chart. The combination of these three bullets will drive the right outcomes. The right outcomes sometimes drive an organizational chart adjustment, but in most cases, organizational shifts are not required.
Think of it this way, if you move a handful of workloads to the cloud, the majority of your IT portfolio will still be managed as business-as-usual, so a major organizational shift just for the cloud likely will not make sense. If I have 100 apps in my IT portfolio and I move 3 apps to the cloud, then would I re-organize around the 3 apps? Or would I keep my organization intact for the 97 apps and adapt only where I must adapt for the 3 cloud apps?
The IT Organization is about the sum of the IT Pros
From a people perspective, the importance of being intentional and communicative cannot be overstated. Senior management should quantify the vision for the IT organization and articulate how Office 365 fits into that vision. It is important to remember that IT Pros are real people with real families and lives outside of work. Many IT Pros worry that the cloud means that they do not have a job in the future. That, of course, is not true. Just as the centralization of the electrical grid did not eliminate the need for electricians, the centralization of the business productivity grid into the cloud does not eliminate the need for the IT Pro. But just as the role of an electrician evolved as the generation of power moved from the on-premise-water-wheel to the utility grid, the role of IT Pro will evolve as business productivity services move to the cloud. The electrician’s role evolved to be more focused on the business-use of the electrical grid. So too will the IT Pro’s role evolve to support the business value realization of the business productivity services. We intend to help with that journey in future blog posts focused on the Consumption and Productivity category.
As senior management plans through the cloud, we recommend that they dig into at least the following role groupings to plan how each will evolve with respect to Office 365 workloads:
Engineering / Tier 3 / Workload or Service Owners…will we still support servers, or will we focus on tenant management and business improvement projects?
Service Desk Tiers and Service Desk Managers…will we support end-users in the same way? With the same documentation? Will our metrics stay the same, or should they evolve?
Major Incident Managers…will we still run bridges for the Office 365 workloads? How will those bridges be initiated? Will our team’s metrics evolve? Given that many of the MSR metrics come from our Major Problem Reviews, is our team’s importance increasing?
Monitoring Engineers and Monitoring Managers…will we accountable for whether we miss something with monitoring for Office 365 workloads? Or perhaps do we support the monitoring service with the Tier 3 engineers being accountable for the rule sets? Should we focus on building a Service Monitoring Service?
Change and Release Managers…how are we going to absorb the evergreen changes and the pace-of-change from Microsoft and still achieve the required outcomes of our Change and Release Management processes?
As you spend time in the Monitoring and Major Incident Management content in this blog series, I encourage you to think through how implementation of the content may change things for the IT Pros using that example. If you implement the monitoring recommendations, will it be simply business-as-usual for your monitoring team? What about the Tier 3 workload team? Or, perhaps is it a shift in how things are done? Perhaps for your on-premise world, the monitoring team owns the monitoring tool and the installed Exchange monitoring management packs. Perhaps in practice, when there is an outage on-premise, the Service Desk recognizes the outage based on call patterns, and then they initiate an incident bridge. Perhaps once the bridge is underway, someone then opens the monitoring tool to look for a possible root cause of the outage. Will that same approach continue in the cloud for Exchange Online, or should we look to evolve that? Perhaps in the cloud we should have the Tier 3 workload team be accountable for missed by monitoring for any end-to-end impact for Exchange regardless of where root cause lies. Perhaps we should have the monitoring team be accountable for the monitoring service with metrics like we describe here. And perhaps we should review both the Exchange monitoring metrics and the Monitoring Service metrics (and any metric-misses) every month in a Monthly Service Review (MSR) with the IT executive team as covered in #3 above. What I describe here is usually a pretty big, yet desirable, culture shift for most IT teams.
Some customers want hands-on assistance
As I mentioned, I get these questions often. Some customers want Microsoft to help guide them on the IT Pro and organizational front. In response to customer requests, my peers and I have created a 3-day, on-site course for IT Executives and IT Management to help them plan for the people side of the change. The workshop focuses on the scenarios, personas and metrics for the evolution discussed in this blog post. The workshop also helps develop employee communications and resistance management plans. The workshop is part of the Adoption and Change Management Services from Microsoft. Ask your Technical Account Manager about the “Managing Change for IT Pros: Office 365†workshop, or find me onTwitter @carrollm_itsm.
Looking ahead
My goal with this blog post is to get everyone thinking. I hope that the commentary was helpful. We’ll jump back into the scenarios in the next post which will focus on Evergreen Management.
Announcing the public preview of the Office 365 Adoption Content Pack in PowerBI
Understanding how your users adopt and use Office 365 is critical for you as an Office 365 admin. It allows you to plan targeted user training and communication to increase usage and to get the most out of Office 365.
Today, we’re pleased to announce the public preview of the Office 365 Adoption Content Pack in Power BI, which enables customers to get more out of Office 365.
The content pack builds on the usage reports in the Office 365 admin center and lets admins further visualize and analyze their Office 365 usage data, create custom reports, share insights and understand how specific regions or departments use Office 365.
It gives you a cross-product view of how users communicate and collaborate making is easy for you to decide where to prioritize training efforts and to provide more targeted user communication.
Read the blog post on Office blogs for all details:
If you have questions, please post them in the Adoption Content Pack group in the Microsoft Tech Community. Also, join us for an Ask Microsoft Anything (AMA) session, hosted by the Microsoft Tech Community on June 7, 2017 at 9 a.m. PDT. This live online event will give you the opportunity to connect with members of the product and engineering teams who will be on hand to answer your questions and listen to feedback. Add the event to your calendar and join us in the Adoption Content Pack in Power BI AMA group.
Announcing the public preview of the Office 365 Adoption Content Pack in PowerBI
Understanding how your users adopt and use Office 365 is critical for you as an Office 365 admin. It allows you to plan targeted user training and communication to increase usage and to get the most out of Office 365.
Today, we’re pleased to announce the public preview of the Office 365 Adoption Content Pack in Power BI, which enables customers to get more out of Office 365.
The content pack builds on the usage reports in the Office 365 admin center and lets admins further visualize and analyze their Office 365 usage data, create custom reports, share insights and understand how specific regions or departments use Office 365.
It gives you a cross-product view of how users communicate and collaborate making is easy for you to decide where to prioritize training efforts and to provide more targeted user communication.
Read the blog post on Office blogs for all details:
If you have questions, please post them in the Adoption Content Pack group in the Microsoft Tech Community. Also, join us for an Ask Microsoft Anything (AMA) session, hosted by the Microsoft Tech Community on June 7, 2017 at 9 a.m. PDT. This live online event will give you the opportunity to connect with members of the product and engineering teams who will be on hand to answer your questions and listen to feedback. Add the event to your calendar and join us in the Adoption Content Pack in Power BI AMA group.
We are excited to announce our second major update of Office Online Server (OOS), which allows organizations to deliver browser-based versions of Word, PowerPoint, Excel and OneNote to users from their own datacenters.
In this release, we officially offer support for Windows Server 2016, which has been highly requested. If you are running Windows Server 2016, you can now install OOS on it. Please verify that you have the latest version of the OOS release to ensure the best experience.
This release includes the following improvements:
Performance improvements to co-authoring in PowerPoint Online
Equation viewing in Word Online
New navigation pane in Word Online
Improved undo/redo in Word Online
Enhanced W3C accessibility support for users that rely on assistive technologies
Accessibility checkers for all applications to ensure that all Office documents can be read and authored by people with different abilities
More about Office Online Server
Microsoft recognizes that many organizations still value running server products on-premises for a variety of reasons. With Office Online Server, you get the same functionality we offer with Office Online in your own datacenter. OOS is the successor to Office Web Apps Server 2013 and we have had three releases starting from our initial launch in May of 2016.
Office Online Server scales well for your enterprise whether you have 100 employees or 100,000. The architecture enables one OOS farm to serve multiple SharePoint, Exchange and Skype for Business instances. OOS is designed to work with SharePoint Server 2016, Exchange Server 2016 and Skype for Business Server 2015. It is also backwards compatible with SharePoint Server 2013, Lync Server 2013 and, in some scenarios, with Exchange Server 2013. You can also integrate other products with OOS through our public APIs.
How do I get OOS/download the update?
If you already have OOS, we encourage you to visit the Volume License Servicing Center to download the April 17 release. You must uninstall the previous version of OOS to install this release. We only support the latest version of OOS with bug fixes and security patches, available via the Microsoft Updates Download Center.
Customers who do not yet have OOS but have a Volume Licensing account can download OOS from the Volume License Servicing Center at no cost and will have view-only functionality, which includes PowerPoint sharing in Skype for Business. Customers that require document creation, edit and save functionality in OOS need to have an on-premises Office Suite license with Software Assurance or an Office 365 ProPlus subscription. For more information on licensing requirements, please refer to our product terms.
We are excited to announce our second major update of Office Online Server (OOS), which allows organizations to deliver browser-based versions of Word, PowerPoint, Excel and OneNote to users from their own datacenters.
In this release, we officially offer support for Windows Server 2016, which has been highly requested. If you are running Windows Server 2016, you can now install OOS on it. Please verify that you have the latest version of the OOS release to ensure the best experience.
This release includes the following improvements:
Performance improvements to co-authoring in PowerPoint Online
Equation viewing in Word Online
New navigation pane in Word Online
Improved undo/redo in Word Online
Enhanced W3C accessibility support for users that rely on assistive technologies
Accessibility checkers for all applications to ensure that all Office documents can be read and authored by people with different abilities
More about Office Online Server
Microsoft recognizes that many organizations still value running server products on-premises for a variety of reasons. With Office Online Server, you get the same functionality we offer with Office Online in your own datacenter. OOS is the successor to Office Web Apps Server 2013 and we have had three releases starting from our initial launch in May of 2016.
Office Online Server scales well for your enterprise whether you have 100 employees or 100,000. The architecture enables one OOS farm to serve multiple SharePoint, Exchange and Skype for Business instances. OOS is designed to work with SharePoint Server 2016, Exchange Server 2016 and Skype for Business Server 2015. It is also backwards compatible with SharePoint Server 2013, Lync Server 2013 and, in some scenarios, with Exchange Server 2013. You can also integrate other products with OOS through our public APIs.
How do I get OOS/download the update?
If you already have OOS, we encourage you to visit the Volume License Servicing Center to download the April 17 release. You must uninstall the previous version of OOS to install this release. We only support the latest version of OOS with bug fixes and security patches, available via the Microsoft Updates Download Center.
Customers who do not yet have OOS but have a Volume Licensing account can download OOS from the Volume License Servicing Center at no cost and will have view-only functionality, which includes PowerPoint sharing in Skype for Business. Customers that require document creation, edit and save functionality in OOS need to have an on-premises Office Suite license with Software Assurance or an Office 365 ProPlus subscription. For more information on licensing requirements, please refer to our product terms.
In the modern world, organizations are transforming how they work with their partners and customers. This means seizing new opportunities quickly, reinventing business processes, and delivering greater value to customers. More important than ever are the strong and trusted relationships that allow for employees to collaborate with partners, contractors and customers outside the business.
At Microsoft, our mission is to empower every person and every organization on the planet to achieve more and we can do this by helping organizations work together, better. Business-to-business collaboration (B2B collaboration) allows Office 365 customers to provide external user accounts with secure access to documents, resources, and applications—while maintaining control over internal data. This let’s your employees work with anyone outside your business (even if they don’t have Office 365) as if they’re a user in your business.
There’s no need to add external users to your directory, sync them, or manage their lifecycle; IT can invite collaborators to use any email address—Office 365, on-premises Microsoft Exchange, or even a personal address (Outlook.com, Gmail, Yahoo!, etc.)—and even set up conditional access policies, including multi-factor authentication. Your developers can use the Azure AD B2B colloboration APIs to write applications that bring together different organizations in a secure way—and deliver a seamless and intuitive end user experience.
B2B collaboration is a feature provided by Microsoft’s cloud-based user authentication service, Azure AD. Office 365 uses Azure AD to manage user accounts and is included as part of your Office 365 scubscription. For more information on Office 365 and the Azure AD version that is included visit the technical documentation.
What you need to know about Azure AD B2B collaboration and Office 365:
Work with any user from any partner
Partners use their own credentials
No requirement for partners to use Azure AD
No external directories or complex set-up required
Simple and secure collaboration
Provide access to any corporate application or resource
Seamless user experiences
Enterprise-grade security for applications and data
No management overhead
No external account or password management
No sync or manual account lifecycle management
No external administrative overhead
Over 3 million users from thousands of business have already been using Azure AD B2B collaboration capabilities available through public preview. When we talk to our customers, 97% have told us Azure AD B2B collaboration is very important to them. We have spent countless hours with these customers diving into how we can serve their needs better with Azure AD B2B collaboration. Today’s announcement would not be possible without their partnership.
In the modern world, organizations are transforming how they work with their partners and customers. This means seizing new opportunities quickly, reinventing business processes, and delivering greater value to customers. More important than ever are the strong and trusted relationships that allow for employees to collaborate with partners, contractors and customers outside the business.
At Microsoft, our mission is to empower every person and every organization on the planet to achieve more and we can do this by helping organizations work together, better. Business-to-business collaboration (B2B collaboration) allows Office 365 customers to provide external user accounts with secure access to documents, resources, and applications—while maintaining control over internal data. This let’s your employees work with anyone outside your business (even if they don’t have Office 365) as if they’re a user in your business.
There’s no need to add external users to your directory, sync them, or manage their lifecycle; IT can invite collaborators to use any email address—Office 365, on-premises Microsoft Exchange, or even a personal address (Outlook.com, Gmail, Yahoo!, etc.)—and even set up conditional access policies, including multi-factor authentication. Your developers can use the Azure AD B2B colloboration APIs to write applications that bring together different organizations in a secure way—and deliver a seamless and intuitive end user experience.
B2B collaboration is a feature provided by Microsoft’s cloud-based user authentication service, Azure AD. Office 365 uses Azure AD to manage user accounts and is included as part of your Office 365 scubscription. For more information on Office 365 and the Azure AD version that is included visit the technical documentation.
What you need to know about Azure AD B2B collaboration and Office 365:
Work with any user from any partner
Partners use their own credentials
No requirement for partners to use Azure AD
No external directories or complex set-up required
Simple and secure collaboration
Provide access to any corporate application or resource
Seamless user experiences
Enterprise-grade security for applications and data
No management overhead
No external account or password management
No sync or manual account lifecycle management
No external administrative overhead
Over 3 million users from thousands of business have already been using Azure AD B2B collaboration capabilities available through public preview. When we talk to our customers, 97% have told us Azure AD B2B collaboration is very important to them. We have spent countless hours with these customers diving into how we can serve their needs better with Azure AD B2B collaboration. Today’s announcement would not be possible without their partnership.
We say this all the time, but it’s worth repeating here: we believe that transparency is key to earning customer trust. When you entrust your data to the Microsoft Cloud, we use advanced security technology and cryptography to safeguard your data. Our compliance with US and international standards is independently audited, and we’re transparent on many levels—from how we handle legal demands for customer data to the security of our code.
We do these things not just to be transparent, but to also make it easier for you to perform your own risk assessment of our cloud services. And we do these things to help you understand how the controls within our cloud services meet the security, compliance, and privacy requirements of your organization.
Service Assurance
Many of our customers in regulated industries are subject to extensive compliance requirements. To perform their own risk assessments, customers often need in-depth information on how Office 365 maintains the security and privacy of their data. Office 365 is committed to the security and privacy of customer data in its cloud services and to earning customer trust by providing a transparent view of its operations, and easy access to independent compliance reports and assessments.
The Service Assurance area of the Security & Compliance Center provides information about how Microsoft’s cloud services maintain security, privacy and compliance with global standards. It includes independent, third-party audit reports for Office 365, Yammer, Azure, Dynamics 365, and Intune, as well as implementation and testing details for the security, privacy, and compliance controls used by Office 365 to protect Customer Data.
Audited Controls
The Audited Controls area of Service Assurance provides information about how the controls used within Office 365 meet security, compliance, and privacy requirements. With Audited Controls, we have mapped our internal control system to other standards, including International Organization for Standardization (ISO) 27001:2013, ISO 27018:2014, and now NIST 800-53.
Using the Audited Controls feature, customers can perform their own assessment of the risks of using Office 365. Customers view the details of a given control, that includes:
Control ID (as assigned by the mapped standard)
Test status (whether the control has passed testing)
Test date (when the control was last tested)
Tested by (typically third-party auditors or Microsoft)
Control implementation details (how the control is implemented)
Testing performed to evaluate control effectiveness (how the control was tested)
Management responses (for any findings from any audits)
Office 365 Audited Controls for NIST 800-53
Microsoft’s internal control system is based on the National Institute of Standards and Technology (NIST) special publication 800-53, and Office 365 has been accredited to latest NIST 800-53 standard as a result of an audit through the Federal Risk and Authorization Management Program (FedRAMP) using the test criteria defined in NIST 800-53A (Rev. 4).
Today, we are pleased to announce the release of the Office 365 Audited Controls for NIST 800-53.The information we have published for this standard represents the results of a third-party audit of Office 365 and can help you better understand how Microsoft has implemented an Information Security Management System to manage and control information security risks related to Office 365. In addition, this information provides you with insights into the implementation and testing of controls designed to maintain the confidentiality, integrity, and availability of Customer Data in Office 365.
The Office 365 Audited Controls for NIST 800-53 include 695 individual controls across 17 control domains:
Control Domain
Intended to Help You To…
Access Control
Understand how Microsoft addresses access control policies and procedures, account management, access enforcement, information flow enforcement, separation of duties, least privilege, unsuccessful login attempts, system use notification, previous login notification, concurrent session control, session locks and termination, access control supervision and review, permitted actions without identification or authentication, automated marking, security attributes, remote and wireless access, access control for mobile devices, use of external information systems and information sharing, publicly accessible content, data mining protections, access control decisions and reference monitors for Office 365.
Awareness and Training
Understand how Microsoft addresses security awareness and training policies and procedures for Office 365 personnel, and how Microsoft addresses role-based security, security training and security training records, and contacts with security groups and associations.
Audit and Accountability
Understand how Microsoft addresses audit and accountability policies and procedures for Office 365, including audit events, contents of audit records, audit storage capacity, processing failures, review, analysis, reporting, reduction and protection of audit information, non-repudiation, audit generation and record retention, monitoring for information disclosure, session audits, and cross-organizational audits.
Security Assessment and Authorization
Understand how Microsoft addresses security assessments for Office 365, including system interconnections, security certification, security authorization, continuous monitoring, penetration testing, and plans of actions and milestones.
Configuration Management
Understand how Microsoft addresses configuration management for Office 365, including baseline configuration management, change control, security impact analysis, access restrictions for change, information system inventory, configuration management plans, and software-usage restrictions.
Contingency Planning
Understand how Microsoft addresses contingency planning related policies and procedures for Office 365, including contingency plans, plan testing, plan updating, alternate storage and processing sites, contingency plans for telecommunications services, information system backup, recovery and reconstitution, alternate communication protocols and alternative security mechanisms.
Identification and Authentication
Understand how Microsoft addresses identification and authentication in Office 365, including device and user identification and authentication, identifier and authentication management, cryptographic module authentication, service identification and authentication, adaptive identification and authentication, and re-authentication.
Incident Response
Understand how Microsoft addresses incident response, including policies and procedures, training, and testing in Office 365. Also understand how Microsoft addresses incident monitoring, handling, and reporting, incident response plans and assistance, and information spillage response.
Maintenance Control
Understand how Microsoft addresses maintenance in Office 365, including policies and procedures, maintenance tools and personnel, non-local and timely maintenance.
Media Protection
Understand how Microsoft addresses media protection in Office 365, including policies and procedures and media access, marking, storage, transport, sanitization, use, and downgrading.
Physical and Environmental Protection
Understand how Microsoft addresses physical and environment protection for Office 365, including policies and procedures, physical access authorization, access control, access monitoring, visitor control, emergency shutoff, power, and lighting, fire and water damage protection, temperature and humidity, information leakage, and asset monitoring and tracking.
Planning
Understand how Microsoft addresses security planning for Office 365, including system security plans and updates, rules of behavior, security-related activity planning, information security architecture, and central management.
Personnel Security
Understand how Microsoft addresses personnel security for Office 365, including policies and procedures, personnel screening, termination, transfer, and sanctions, access agreements, and third-party personnel security.
Risk Assessment
Understand how Microsoft addresses risk assessment for Office 365, including risk assessment planning and updates, vulnerability scanning, technical surveillance and countermeasures.
System and Services Acquisition
Understand how Microsoft addresses system and services acquisitions for Office 365, including allocation of resources, system development lifecycle, information system documentation, supply chain protection, trustworthiness, developer configuration testing and security management, tamper resistance and detection, component authenticity, developer screening, and security engineering principles.
System and Communications Protection
Understand how Microsoft addresses system and communications protection for Office 365, including denial-of-service and boundary protection, transmission confidentiality and integrity, cryptographic key protection, public access protection, protection of information at rest, honeypots, honey-clients, concealment and misdirection, operations security, port and I/O device access, mobile code, secure name and address resolution, and detonation chambers.
System and Information Integrity
Understand how Microsoft addresses system and information integrity for Office 365, including flaw remediation, malicious code protection, information system monitoring, security alerts and advisories, information input handling and restrictions, error handling, memory protections, and fail-safe procedures.
You can use the information published for this control set in two ways:
In the Audited Controls area of the Security & Compliance Center, where you can search controls using keywords and control ID numbers, and filter controls to see only those controls that have findings.
2. You can also download the Audited Controls in Excel format and search them offline.
Accessing Service Assurance and Audited Controls
Anyone—and I mean anyone—can access Service Assurance and Audited Controls, including existing customers of Office 365 for business, new customers, and customers evaluating Microsoft online services. When you access Service Assurance for the first time, the first step is to configure your industry and regional settings. Once you have selected regions and industries, you can review and download content, including compliance reports and trust documents, and Audited Controls. For detailed steps to access Service Assurance, see Service assurance in the Office 365 Security & Compliance Center.
You can also download Audited Controls workbooks from the Compliance Guides section of the Service Trust Preview, which is available to anyone with a paid or trial tenant.
Audited Controls Roadmap
The release of the Office 365 Audited Controls for NIST 800-53 represents another milestone in our efforts to be transparent with you about how we operate our cloud services. Our upcoming journey includes work to develop and release Office 365 Audited Controls for Service Organization Controls (SOC) 2, and to develop and release Audited Controls for both Azure and Dynamics 365. In addition, we are developing tools that will allow you to upload your own control framework and map it to Microsoft’s control framework and various standards.
Tens of thousands of organizations already use Office 365 Service Assurance and have indicated that they are saving a significant amount of time in evaluating the security, privacy and compliance of Office 365. We hope you find the Office 365 Audited Controls for NIST 800-53 useful, and we look forward to your feedback.
— Scott Schnoll, Senior Program Manager, Office 365 Customer Experience
One of the challenges concerning those implementing Service Delivery with Office365, is building proof that Office365 complies with regulatory standards and legislation. Service Assurance in Office365 is a primary goal, and if it vital that you understand how Office365 protects your data, especially since Office365 concerns email access, team communication, collaboration, content storage and specifically content viewed and edited in a browser. Service Delivery includes Service assurance, which is an organisational primary goal, and is directly aligned to the C/I/A triad (Confidentiality, Integrity and Availability), being key aspects of information security.
Office365 contains a Service Assurance area which allows Administrators to setup and provide resources to carry out risk assessments and audits, and includes a wealth of reports covering security, and the relevant legislation and standards that Office365 adheres to. I wrote an article for TechNet Blogs which gives a great overview on how to use Office365 Service Assurance (within the Security and Compliance section) here, go check it out!
One of the most useful documents in my view in planning implementations of Office365 is understanding data encryption and data backup and the standards applied. Microsoft have provided audit reports covering their cloud stack (Dynamics CRM, Office365, Yammer and Azure). These SOC and ISO reports include testing and trust principles in these areas:
Data Transmission and Encryption
Security Development Lifecycle
Data Replication and Data Backup
To access these reports, you will need to access the Security and Compliance area in your Office365 tenant.
As said, these cover the Microsoft Cloud Stack, however, the two key documents for Office365 are:
Office 365 ISO 27001-ISO 27018-ISO 27017 – this is an audit document confirming whether Office365 fulfils the standards and criteria against ISO 27001, 27018 and 27017.
Key points:
PII is included in Office365 because it is run over Public Cloud for multi-tenant customers.
Cloud Security is included in Office365 because it is defined as a SaaS (Software as a Service)
All encryption adheres to TLS requirements and hashing (specific)
Office 365 SOC 2 AT 101 Audit Report 2016 – this is an audit document looking at the controls relevant to Security, Availability, Confidentiality and Processing Integrity.
Key points:
Details on the services concerning planning, performance, SLAs, hiring process (including background checks of staff) are provided.
Control Monitoring, Access and Identify Management, Data Transmission (encryption between Microsoft, Client and data centres) are described.
Project requirements through to Final Approval concerning the SDLC process is described
Availability, Data Replication and Backup is covered.
Summary
The above SOC and ISO are extremely useful in aiding any risk assessment that you should take to confirm the service assurance of Office365 going forward. Risk assessments are not a ‘one shot’ task. They should be carried out on an annual basis. The Office365 service is a rich offering of Infrastructure, Software, People, Procedures and Data. Each requires security controls and confirmation that they meet standards which can be dovetailed into your organisation. The audits go into great detail concerning the controls (especially things like Data in Transit / Rest – SSL / TLS). A lot of questions is asked by customers concerning security controls – the video below is a good method of getting you to understand (and your clients) how Microsoft ensures proactive protection, and you should definitely check out the Microsoft Trust Centre for great information concerning encryption.
Learn to make the most of Office 365 innovation by bringing cloud innovation to your on-premises SharePoint infrastructure. Why? Cloud computing has become a popular and successful computing model that enables organizations to reduce their capital and operational expenditures, renew IT innovation, and gain the advantage of more rapid software delivery to meet their business needs. The session below allows you to get get a detailed overview of the latest innovation in cloud-connected hybrid scenarios, along with a look at the capabilities and features in the hybrid SharePoint and Office 365 roadmap.
Microsoft has released a tool, called SARA, that can help diagnose issues with Office 365. Currently, its configured to help setting up Outlook with Office365.
SARA is the Support and Recovery Assistant for Office365, and can help diagnose issues from you entering the Office365 account, and then using the Support topic options to get help with. SARA is an on-demand application, so it only needs to be used when there is a problem indicated. Of course, access to the Office365 tenant will be required to use this tool! Its early days for SARA as I write this quick blog,, but, I guess it would be useful to keep an eye on this tool, as Microsoft continues to upgrade it to help support issues with other products in the Office365 suite.
Check the below video for more information, and download link is below the video.
Had some fun trying to get a domain validated with Office365. Here’s the issue.
When going for validation, you will be given instructions on setting a TXT or MX record and will be given a validation code to enter with your provider. If the provider given on the page is not yours you could then take a look at the
help screen that gives more details and step by step instructions.
However, it is difficult to ascertain whether the TXT record has been set.
NSLOOKUP comes to the rescue:
Bring up a Command Prompt
Enter NSLOOKUP
type set q=txt
Enter your Domain Name
You should then get a
response that looks something like this:
Non-authoritative answer:
yourdomain.com text =
“MS=ms1625352”
yourdomain.com nameserver = ns2.123-reg.co.uk
yourdomain.com nameserver = ns.123-reg.co.uk
ns1 internet address = xxx.xxx.xxx.xxx
ns2 internet address = xxx.xxx.xxx.xxx
Notice the MS line above – thats the TXT record, and thats what the validation looks for. If you see this, then your domain should be validated successfully.