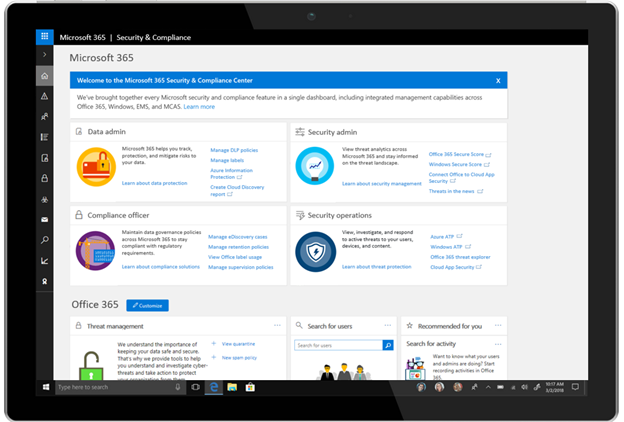
Last year, at Inspire, we announced Microsoft 365, which brings together Office 365, Windows 10, and Enterprise Mobility + Security to deliver a complete, intelligent, and secure solution for the modern workspace. As part of the Microsoft 365 vision and expanding on the unified administration experience we started with the Microsoft 365 admin center, we have created the Microsoft 365 security and compliance center.
The Microsoft 365 security and compliance center maintains the centralized experience, intelligence, and customization that Office 365 security and compliance center offers today. In addition, it also enables data administrators, compliance officers, security administrators, and security operations to discover security and compliance controls across Office 365, Enterprise Mobility + Security, and Windows in a single place. For example, data administrators can easily access features like Azure Information Protection and Microsoft Cloud App Security to help them detect, classify, protect, and report on their data.
The Microsoft 365 Security and Compliance Center
Over the coming months, we will continue integrating and streamlining administration experiences across Microsoft 365. To help organizations optimize their resources we will add new capabilities to help deploy and manage security and compliance solutions. We will also continue to improve the efficiency of the security and compliance administrator’s user experience, so they can complete their tasks quickly to get more done with their day.
The Microsoft 365 security and compliance center is rolling out now. Once deployed, administrators can login as they usually do, or navigate to https://protection.microsoft.com to try out the new security and compliance experiences. In addition, they can also navigate to the Microsoft 365 security and compliance center from the Microsoft 365 admin center . Administrators will still be able to configure and manage their Office 365 security and compliance settings within the new Microsoft 365 security and compliance center.
Last year, at Inspire, we announced Microsoft 365, which brings together Office 365, Windows 10, and Enterprise Mobility + Security to deliver a complete, intelligent, and secure solution for the modern workspace. As part of the Microsoft 365 vision and expanding on the unified administration experience we started with the Microsoft 365 admin center, we have created the Microsoft 365 security and compliance center.
The Microsoft 365 security and compliance center maintains the centralized experience, intelligence, and customization that Office 365 security and compliance center offers today. In addition, it also enables data administrators, compliance officers, security administrators, and security operations to discover security and compliance controls across Office 365, Enterprise Mobility + Security, and Windows in a single place. For example, data administrators can easily access features like Azure Information Protection and Microsoft Cloud App Security to help them detect, classify, protect, and report on their data.
The Microsoft 365 Security and Compliance Center
Over the coming months, we will continue integrating and streamlining administration experiences across Microsoft 365. To help organizations optimize their resources we will add new capabilities to help deploy and manage security and compliance solutions. We will also continue to improve the efficiency of the security and compliance administrator’s user experience, so they can complete their tasks quickly to get more done with their day.
The Microsoft 365 security and compliance center is rolling out now. Once deployed, administrators can login as they usually do, or navigate to https://protection.microsoft.com to try out the new security and compliance experiences. In addition, they can also navigate to the Microsoft 365 security and compliance center from the Microsoft 365 admin center . Administrators will still be able to configure and manage their Office 365 security and compliance settings within the new Microsoft 365 security and compliance center.
Last year, at Inspire, we announced Microsoft 365, which brings together Office 365, Windows 10, and Enterprise Mobility + Security to deliver a complete, intelligent, and secure solution for the modern workspace. As part of the Microsoft 365 vision and expanding on the unified administration experience we started with the Microsoft 365 admin center, we have created the Microsoft 365 security and compliance center.
The Microsoft 365 security and compliance center maintains the centralized experience, intelligence, and customization that Office 365 security and compliance center offers today. In addition, it also enables data administrators, compliance officers, security administrators, and security operations to discover security and compliance controls across Office 365, Enterprise Mobility + Security, and Windows in a single place. For example, data administrators can easily access features like Azure Information Protection and Microsoft Cloud App Security to help them detect, classify, protect, and report on their data.
The Microsoft 365 Security and Compliance Center
Over the coming months, we will continue integrating and streamlining administration experiences across Microsoft 365. To help organizations optimize their resources we will add new capabilities to help deploy and manage security and compliance solutions. We will also continue to improve the efficiency of the security and compliance administrator’s user experience, so they can complete their tasks quickly to get more done with their day.
The Microsoft 365 security and compliance center is rolling out now. Once deployed, administrators can login as they usually do, or navigate to https://protection.microsoft.com to try out the new security and compliance experiences. In addition, they can also navigate to the Microsoft 365 security and compliance center from the Microsoft 365 admin center . Administrators will still be able to configure and manage their Office 365 security and compliance settings within the new Microsoft 365 security and compliance center.
In this mobile-first and cloud-first world, Microsoft is committed to build and maintain a partnership with you to meet your security, compliance, and privacy needs. When your organization’s data was on-premises, it was 100 percent your responsibility to meet all regulatory requirements. As you move your data to a Microsoft Cloud service, such as Office 365, Azure, or Dynamics 365, we partner with you to help you achieve compliance under the shared responsibility model.
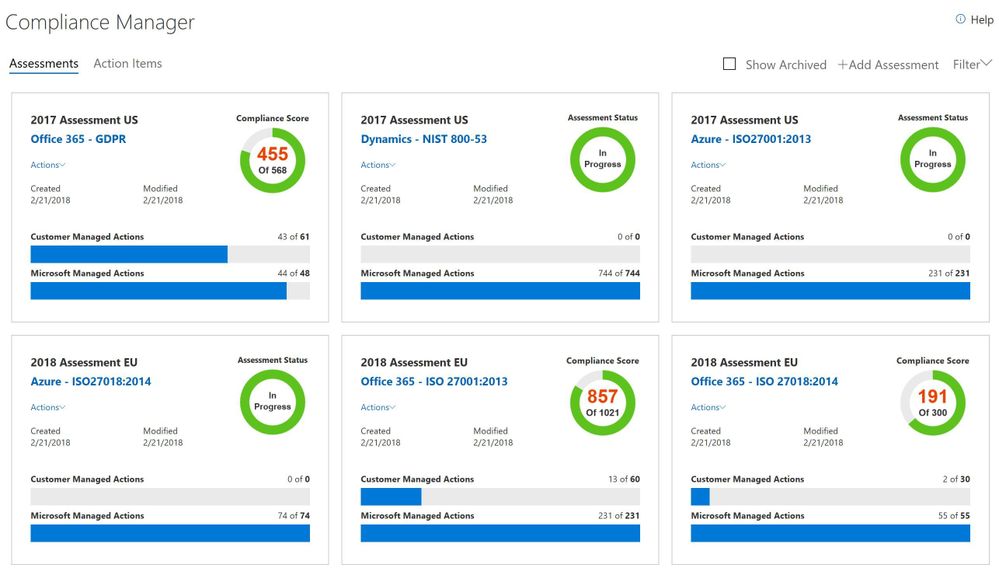
To support your organization’s compliance journey when using Microsoft Cloud services, Microsoft released Compliance Manager Preview last November. Today, we are building upon this partnership by announcing thatis now generally available as an additional value for Azure, Dynamics 365, and Office 365 Business and Enterprise subscribers in public clouds[1].
Compliance Manager empowers your organization to manage your compliance activities from one place with three key capabilities:
- Helps you perform on-going risk assessments, now with Compliance Score
Compliance Manager is a cross-Microsoft Cloud services solution designed to help organizations meet complex compliance obligations, including the EU GDPR, ISO 27001, ISO 27018, NIST 800- 53, NIST 800- 171, and HIPAA[2].
It enables your organization to perform on-going risk assessments for what is identified as Microsoft’s responsibilities by evaluating detailed implementation and test details of our internal controls. We are committed to be transparent about how we process and protect your data so that you can trust Microsoft and leverage the technology we provide.
Compliance Manager dashboard with Compliance Score
We also provide you the information and tools to conduct self-assessment for your responsibilities of meeting regulatory requirements. Now with Compliance Score[3] —a new feature for Compliance Manager—you can gain visibility into your organization’s compliance stature with a risk-based score reference.
The Compliance Score is based on the operating effectiveness of internal controls managed by both Microsoft and you. Failure to implement different controls will have different levels of risk. We assign a weight to each control based on the level of risk involved when you do not implement a control or fail to pass the test of a control. From the detailed information page of each assessment, you can find an assigned risk-based score for each control item, and prioritize your tasks and make better implementation plans based on the risk involved.
- Provides you actionable insights, now from a certification/regulation view
One of the biggest pain points we heard from organizations is finding talent with expertise in both industrial compliance and technology solutions. Most of the time, compliance personnel have in-depth knowledge of industrial regulations and standards, while IT professionals have the technology tools that help the company to protect data. Because there is lack of connections between these two areas, meeting data protection and regulatory requirements becomes a very disjointed process.
To help reduce this challenge, Compliance Manager builds the connection between the data protection capabilities and the regulatory requirements, so now you know which technology solutions you can leverage to meet certain compliance obligations.
In response to feedback from customers, this product update re-organizes the control information from the “Microsoft control framework” view (e.g. MS-control AR-0104) to a “certification controls or regulatory article” view (e.g. ISO 27001:2013: C.5.1.a). Before, one Microsoft control corresponded to one or multiple certification controls or regulatory articles, and you needed to take many actions to implement one control. In the newly updated view, you can see customer actions for each certification or regulatory control, and the specific actions recommended for each control[4].
 Detailed information page of an assessment
Detailed information page of an assessment
You still have the same experience for each control, i.e., finding customer actions with step-by-step guidance to guide you through implementing internal controls and developing business processes for your organization. We will keep the preview view (MS-control view) till the end of August 2018 for you to migrate the information into the new view.
- Simplifies your journey to manage compliance activities, now with the capability to create multiple assessments for each standard and regulation
According to the report, Cost of Compliance 2017 from Thomson Reuters, 32 percent of companies spend more than 4 hours per week creating and amending audit reports. It’s very time-consuming to collect evidence and demonstrate effective control implementation for auditing activities.
Compliance Manager enables you to assign, track, and record your compliance activities, so you can collaborate across teams and manage your documents for creating audit reports more easily.
By using group functionality, you can now create multiple assessments for any standard or regulation that is available to you in Compliance Manager by time, by teams, or by business units. For example, you can create a GDPR assessment for the 2018 group and another one for the 2019 group. Similarly, you can create an ISO 27001 assessment for your business units located in the U.S. and another one for your business units located in Europe. This functionality gives you a more robust way to manage compliance activities based on your organizational needs for performing risk assessments.
We are excited to launch Compliance Manager with these updates to make it a better experience for you. We’d like to hear your feedback on the product to keep improving functionality, adding new features, and enhancing existing ones. Sign in totoday using your Azure, Dynamics 365, or Office 365 account, and give us feedback via the Feedback button at the bottom right corner of Compliance Manager. You can also learn more about Compliance Manager in this, “Simplify your compliance journey with Service Trust Portal and Compliance Manager”, and on the Compliance Manager support page.
Work with a partner who knows GDPR
Microsoft works with partners globally to address customer needs around GDPR. We have several partners today offering Microsoft-based solutions that include an overall set of controls and capabilities to help customers meet their GDPR requirements. Here’s our list of global partners we currently work with to meet the growing demand for GDPR support.
Product scope[2]
You can find the coverage of regulations and standards for each Microsoft cloud service below as of February 2018:
- Office 365: Detailed information about Microsoft’s internal controls for and recommended customer actions for GDPR, ISO 27001, ISO 27018, NIST 800- 53, NIST 800- 171, and HIPAA
- Azure: Detailed information about Microsoft’s internal controls for ISO 27001 and ISO 27018
- Dynamics 365: Detailed information about Microsoft’s internal controls for NIST 800- 53; recommended customer actions for partial GDPR controls managed by organizations
[1] Note that Office 365 GCC customers can access Compliance Manager; however, users should evaluate whether to use the document upload feature of Compliance Manager, as the storage for document upload is compliant with Office 365 Tier C only. Compliance Manager is not yet available in sovereign clouds including Office 365 U.S. Government Community High (GCC High), Office 365 Department of Defense (DoD), Office 365 Operated by 21 Vianet, and Office 365 Germany.
[2] Coverage of regulations and standards in Compliance Manager varies by product. We will keep adding and updating the information in the future and our goal is to provide a similar experience of using Compliance Manager for all Microsoft Cloud services.
[3] Compliance Score is only available for Office 365 currently. Our goal is to provide Compliance Score for all Microsoft Cloud services in the near future.
[4] Compliance Manager is a dashboard that provides the Compliance Score and a summary of your data protection and compliance stature as well as recommendations to improve data protection and compliance. This is a recommendation; it is up to you to evaluate and validate the effectiveness of customer controls as per your regulatory environment. Recommendations from Compliance Manager and Compliance Score should not be interpreted as a guarantee of compliance.
The following is provided from Microsoft Security and Compliance blogs at TechCommunity:
In this mobile-first and cloud-first world, Microsoft is committed to build and maintain a partnership with you to meet your security, compliance, and privacy needs. When your organization’s data was on-premises, it was 100 percent your responsibility to meet all regulatory requirements. As you move your data to a Microsoft Cloud service, such as Office 365, Azure, or Dynamics 365, we partner with you to help you achieve compliance under the shared responsibility model.
To support your organization’s compliance journey when using Microsoft Cloud services, Microsoft released Compliance Manager Preview last November. Today, we are building upon this partnership by announcing thatis now generally available as an additional value for Azure, Dynamics 365, and Office 365 Business and Enterprise subscribers in public clouds[1].
Compliance Manager empowers your organization to manage your compliance activities from one place with three key capabilities:
- Helps you perform on-going risk assessments, now with Compliance Score
Compliance Manager is a cross-Microsoft Cloud services solution designed to help organizations meet complex compliance obligations, including the EU GDPR, ISO 27001, ISO 27018, NIST 800- 53, NIST 800- 171, and HIPAA[2].
It enables your organization to perform on-going risk assessments for what is identified as Microsoft’s responsibilities by evaluating detailed implementation and test details of our internal controls. We are committed to be transparent about how we process and protect your data so that you can trust Microsoft and leverage the technology we provide.
Compliance Manager dashboard with Compliance Score
We also provide you the information and tools to conduct self-assessment for your responsibilities of meeting regulatory requirements. Now with Compliance Score[3] —a new feature for Compliance Manager—you can gain visibility into your organization’s compliance stature with a risk-based score reference.
The Compliance Score is based on the operating effectiveness of internal controls managed by both Microsoft and you. Failure to implement different controls will have different levels of risk. We assign a weight to each control based on the level of risk involved when you do not implement a control or fail to pass the test of a control. From the detailed information page of each assessment, you can find an assigned risk-based score for each control item, and prioritize your tasks and make better implementation plans based on the risk involved.
- Provides you actionable insights, now from a certification/regulation view
One of the biggest pain points we heard from organizations is finding talent with expertise in both industrial compliance and technology solutions. Most of the time, compliance personnel have in-depth knowledge of industrial regulations and standards, while IT professionals have the technology tools that help the company to protect data. Because there is lack of connections between these two areas, meeting data protection and regulatory requirements becomes a very disjointed process.
To help reduce this challenge, Compliance Manager builds the connection between the data protection capabilities and the regulatory requirements, so now you know which technology solutions you can leverage to meet certain compliance obligations.
In response to feedback from customers, this product update re-organizes the control information from the “Microsoft control framework” view (e.g. MS-control AR-0104) to a “certification controls or regulatory article” view (e.g. ISO 27001:2013: C.5.1.a). Before, one Microsoft control corresponded to one or multiple certification controls or regulatory articles, and you needed to take many actions to implement one control. In the newly updated view, you can see customer actions for each certification or regulatory control, and the specific actions recommended for each control[4].
Detailed information page of an assessment
You still have the same experience for each control, i.e., finding customer actions with step-by-step guidance to guide you through implementing internal controls and developing business processes for your organization. We will keep the preview view (MS-control view) till the end of August 2018 for you to migrate the information into the new view.
- Simplifies your journey to manage compliance activities, now with the capability to create multiple assessments for each standard and regulation
According to the report, Cost of Compliance 2017 from Thomson Reuters, 32 percent of companies spend more than 4 hours per week creating and amending audit reports. It’s very time-consuming to collect evidence and demonstrate effective control implementation for auditing activities.
Compliance Manager enables you to assign, track, and record your compliance activities, so you can collaborate across teams and manage your documents for creating audit reports more easily.
By using group functionality, you can now create multiple assessments for any standard or regulation that is available to you in Compliance Manager by time, by teams, or by business units. For example, you can create a GDPR assessment for the 2018 group and another one for the 2019 group. Similarly, you can create an ISO 27001 assessment for your business units located in the U.S. and another one for your business units located in Europe. This functionality gives you a more robust way to manage compliance activities based on your organizational needs for performing risk assessments.
We are excited to launch Compliance Manager with these updates to make it a better experience for you. We’d like to hear your feedback on the product to keep improving functionality, adding new features, and enhancing existing ones. Sign in totoday using your Azure, Dynamics 365, or Office 365 account, and give us feedback via the Feedback button at the bottom right corner of Compliance Manager. You can also learn more about Compliance Manager in this, “Simplify your compliance journey with Service Trust Portal and Compliance Manager”, and on the Compliance Manager support page.
Work with a partner who knows GDPR
Microsoft works with partners globally to address customer needs around GDPR. We have several partners today offering Microsoft-based solutions that include an overall set of controls and capabilities to help customers meet their GDPR requirements. Here’s our list of global partners we currently work with to meet the growing demand for GDPR support.
Product scope[2]
You can find the coverage of regulations and standards for each Microsoft cloud service below as of February 2018:
- Office 365: Detailed information about Microsoft’s internal controls for and recommended customer actions for GDPR, ISO 27001, ISO 27018, NIST 800- 53, NIST 800- 171, and HIPAA
- Azure: Detailed information about Microsoft’s internal controls for ISO 27001 and ISO 27018
- Dynamics 365: Detailed information about Microsoft’s internal controls for NIST 800- 53; recommended customer actions for partial GDPR controls managed by organizations
[1] Note that Office 365 GCC customers can access Compliance Manager; however, users should evaluate whether to use the document upload feature of Compliance Manager, as the storage for document upload is compliant with Office 365 Tier C only. Compliance Manager is not yet available in sovereign clouds including Office 365 U.S. Government Community High (GCC High), Office 365 Department of Defense (DoD), Office 365 Operated by 21 Vianet, and Office 365 Germany.
[2] Coverage of regulations and standards in Compliance Manager varies by product. We will keep adding and updating the information in the future and our goal is to provide a similar experience of using Compliance Manager for all Microsoft Cloud services.
[3] Compliance Score is only available for Office 365 currently. Our goal is to provide Compliance Score for all Microsoft Cloud services in the near future.
[4] Compliance Manager is a dashboard that provides the Compliance Score and a summary of your data protection and compliance stature as well as recommendations to improve data protection and compliance. This is a recommendation; it is up to you to evaluate and validate the effectiveness of customer controls as per your regulatory environment. Recommendations from Compliance Manager and Compliance Score should not be interpreted as a guarantee of compliance.
The above was provided from Microsoft Security and Compliance blogs at TechCommunity
In this mobile-first and cloud-first world, Microsoft is committed to build and maintain a partnership with you to meet your security, compliance, and privacy needs. When your organization’s data was on-premises, it was 100 percent your responsibility to meet all regulatory requirements. As you move your data to a Microsoft Cloud service, such as Office 365, Azure, or Dynamics 365, we partner with you to help you achieve compliance under the shared responsibility model.
To support your organization’s compliance journey when using Microsoft Cloud services, Microsoft released Compliance Manager Preview last November. Today, we are building upon this partnership by announcing thatis now generally available as an additional value for Azure, Dynamics 365, and Office 365 Business and Enterprise subscribers in public clouds[1].
Compliance Manager empowers your organization to manage your compliance activities from one place with three key capabilities:
- Helps you perform on-going risk assessments, now with Compliance Score
Compliance Manager is a cross-Microsoft Cloud services solution designed to help organizations meet complex compliance obligations, including the EU GDPR, ISO 27001, ISO 27018, NIST 800- 53, NIST 800- 171, and HIPAA[2].
It enables your organization to perform on-going risk assessments for what is identified as Microsoft’s responsibilities by evaluating detailed implementation and test details of our internal controls. We are committed to be transparent about how we process and protect your data so that you can trust Microsoft and leverage the technology we provide.
Compliance Manager dashboard with Compliance Score
We also provide you the information and tools to conduct self-assessment for your responsibilities of meeting regulatory requirements. Now with Compliance Score[3] —a new feature for Compliance Manager—you can gain visibility into your organization’s compliance stature with a risk-based score reference.
The Compliance Score is based on the operating effectiveness of internal controls managed by both Microsoft and you. Failure to implement different controls will have different levels of risk. We assign a weight to each control based on the level of risk involved when you do not implement a control or fail to pass the test of a control. From the detailed information page of each assessment, you can find an assigned risk-based score for each control item, and prioritize your tasks and make better implementation plans based on the risk involved.
- Provides you actionable insights, now from a certification/regulation view
One of the biggest pain points we heard from organizations is finding talent with expertise in both industrial compliance and technology solutions. Most of the time, compliance personnel have in-depth knowledge of industrial regulations and standards, while IT professionals have the technology tools that help the company to protect data. Because there is lack of connections between these two areas, meeting data protection and regulatory requirements becomes a very disjointed process.
To help reduce this challenge, Compliance Manager builds the connection between the data protection capabilities and the regulatory requirements, so now you know which technology solutions you can leverage to meet certain compliance obligations.
In response to feedback from customers, this product update re-organizes the control information from the “Microsoft control framework” view (e.g. MS-control AR-0104) to a “certification controls or regulatory article” view (e.g. ISO 27001:2013: C.5.1.a). Before, one Microsoft control corresponded to one or multiple certification controls or regulatory articles, and you needed to take many actions to implement one control. In the newly updated view, you can see customer actions for each certification or regulatory control, and the specific actions recommended for each control[4].
Detailed information page of an assessment
You still have the same experience for each control, i.e., finding customer actions with step-by-step guidance to guide you through implementing internal controls and developing business processes for your organization. We will keep the preview view (MS-control view) till the end of August 2018 for you to migrate the information into the new view.
- Simplifies your journey to manage compliance activities, now with the capability to create multiple assessments for each standard and regulation
According to the report, Cost of Compliance 2017 from Thomson Reuters, 32 percent of companies spend more than 4 hours per week creating and amending audit reports. It’s very time-consuming to collect evidence and demonstrate effective control implementation for auditing activities.
Compliance Manager enables you to assign, track, and record your compliance activities, so you can collaborate across teams and manage your documents for creating audit reports more easily.
By using group functionality, you can now create multiple assessments for any standard or regulation that is available to you in Compliance Manager by time, by teams, or by business units. For example, you can create a GDPR assessment for the 2018 group and another one for the 2019 group. Similarly, you can create an ISO 27001 assessment for your business units located in the U.S. and another one for your business units located in Europe. This functionality gives you a more robust way to manage compliance activities based on your organizational needs for performing risk assessments.
We are excited to launch Compliance Manager with these updates to make it a better experience for you. We’d like to hear your feedback on the product to keep improving functionality, adding new features, and enhancing existing ones. Sign in totoday using your Azure, Dynamics 365, or Office 365 account, and give us feedback via the Feedback button at the bottom right corner of Compliance Manager. You can also learn more about Compliance Manager in this, “Simplify your compliance journey with Service Trust Portal and Compliance Manager”, and on the Compliance Manager support page.
Work with a partner who knows GDPR
Microsoft works with partners globally to address customer needs around GDPR. We have several partners today offering Microsoft-based solutions that include an overall set of controls and capabilities to help customers meet their GDPR requirements. Here’s our list of global partners we currently work with to meet the growing demand for GDPR support.
Product scope[2]
You can find the coverage of regulations and standards for each Microsoft cloud service below as of February 2018:
- Office 365: Detailed information about Microsoft’s internal controls for and recommended customer actions for GDPR, ISO 27001, ISO 27018, NIST 800- 53, NIST 800- 171, and HIPAA
- Azure: Detailed information about Microsoft’s internal controls for ISO 27001 and ISO 27018
- Dynamics 365: Detailed information about Microsoft’s internal controls for NIST 800- 53; recommended customer actions for partial GDPR controls managed by organizations
[1] Note that Office 365 GCC customers can access Compliance Manager; however, users should evaluate whether to use the document upload feature of Compliance Manager, as the storage for document upload is compliant with Office 365 Tier C only. Compliance Manager is not yet available in sovereign clouds including Office 365 U.S. Government Community High (GCC High), Office 365 Department of Defense (DoD), Office 365 Operated by 21 Vianet, and Office 365 Germany.
[2] Coverage of regulations and standards in Compliance Manager varies by product. We will keep adding and updating the information in the future and our goal is to provide a similar experience of using Compliance Manager for all Microsoft Cloud services.
[3] Compliance Score is only available for Office 365 currently. Our goal is to provide Compliance Score for all Microsoft Cloud services in the near future.
[4] Compliance Manager is a dashboard that provides the Compliance Score and a summary of your data protection and compliance stature as well as recommendations to improve data protection and compliance. This is a recommendation; it is up to you to evaluate and validate the effectiveness of customer controls as per your regulatory environment. Recommendations from Compliance Manager and Compliance Score should not be interpreted as a guarantee of compliance.
In this mobile-first and cloud-first world, Microsoft is committed to build and maintain a partnership with you to meet your security, compliance, and privacy needs. When your organization’s data was on-premises, it was 100 percent your responsibility to meet all regulatory requirements. As you move your data to a Microsoft Cloud service, such as Office 365, Azure, or Dynamics 365, we partner with you to help you achieve compliance under the shared responsibility model.
To support your organization’s compliance journey when using Microsoft Cloud services, Microsoft released Compliance Manager Preview last November. Today, we are building upon this partnership by announcing thatis now generally available as an additional value for Azure, Dynamics 365, and Office 365 Business and Enterprise subscribers in public clouds[1].
Compliance Manager empowers your organization to manage your compliance activities from one place with three key capabilities:
- Helps you perform on-going risk assessments, now with Compliance Score
Compliance Manager is a cross-Microsoft Cloud services solution designed to help organizations meet complex compliance obligations, including the EU GDPR, ISO 27001, ISO 27018, NIST 800- 53, NIST 800- 171, and HIPAA[2].
It enables your organization to perform on-going risk assessments for what is identified as Microsoft’s responsibilities by evaluating detailed implementation and test details of our internal controls. We are committed to be transparent about how we process and protect your data so that you can trust Microsoft and leverage the technology we provide.
Compliance Manager dashboard with Compliance Score
We also provide you the information and tools to conduct self-assessment for your responsibilities of meeting regulatory requirements. Now with Compliance Score[3] —a new feature for Compliance Manager—you can gain visibility into your organization’s compliance stature with a risk-based score reference.
The Compliance Score is based on the operating effectiveness of internal controls managed by both Microsoft and you. Failure to implement different controls will have different levels of risk. We assign a weight to each control based on the level of risk involved when you do not implement a control or fail to pass the test of a control. From the detailed information page of each assessment, you can find an assigned risk-based score for each control item, and prioritize your tasks and make better implementation plans based on the risk involved.
- Provides you actionable insights, now from a certification/regulation view
One of the biggest pain points we heard from organizations is finding talent with expertise in both industrial compliance and technology solutions. Most of the time, compliance personnel have in-depth knowledge of industrial regulations and standards, while IT professionals have the technology tools that help the company to protect data. Because there is lack of connections between these two areas, meeting data protection and regulatory requirements becomes a very disjointed process.
To help reduce this challenge, Compliance Manager builds the connection between the data protection capabilities and the regulatory requirements, so now you know which technology solutions you can leverage to meet certain compliance obligations.
In response to feedback from customers, this product update re-organizes the control information from the “Microsoft control framework” view (e.g. MS-control AR-0104) to a “certification controls or regulatory article” view (e.g. ISO 27001:2013: C.5.1.a). Before, one Microsoft control corresponded to one or multiple certification controls or regulatory articles, and you needed to take many actions to implement one control. In the newly updated view, you can see customer actions for each certification or regulatory control, and the specific actions recommended for each control[4].
Detailed information page of an assessment
You still have the same experience for each control, i.e., finding customer actions with step-by-step guidance to guide you through implementing internal controls and developing business processes for your organization. We will keep the preview view (MS-control view) till the end of August 2018 for you to migrate the information into the new view.
- Simplifies your journey to manage compliance activities, now with the capability to create multiple assessments for each standard and regulation
According to the report, Cost of Compliance 2017 from Thomson Reuters, 32 percent of companies spend more than 4 hours per week creating and amending audit reports. It’s very time-consuming to collect evidence and demonstrate effective control implementation for auditing activities.
Compliance Manager enables you to assign, track, and record your compliance activities, so you can collaborate across teams and manage your documents for creating audit reports more easily.
By using group functionality, you can now create multiple assessments for any standard or regulation that is available to you in Compliance Manager by time, by teams, or by business units. For example, you can create a GDPR assessment for the 2018 group and another one for the 2019 group. Similarly, you can create an ISO 27001 assessment for your business units located in the U.S. and another one for your business units located in Europe. This functionality gives you a more robust way to manage compliance activities based on your organizational needs for performing risk assessments.
We are excited to launch Compliance Manager with these updates to make it a better experience for you. We’d like to hear your feedback on the product to keep improving functionality, adding new features, and enhancing existing ones. Sign in totoday using your Azure, Dynamics 365, or Office 365 account, and give us feedback via the Feedback button at the bottom right corner of Compliance Manager. You can also learn more about Compliance Manager in this, “Simplify your compliance journey with Service Trust Portal and Compliance Manager”, and on the Compliance Manager support page.
Work with a partner who knows GDPR
Microsoft works with partners globally to address customer needs around GDPR. We have several partners today offering Microsoft-based solutions that include an overall set of controls and capabilities to help customers meet their GDPR requirements. Here’s our list of global partners we currently work with to meet the growing demand for GDPR support.
Product scope[2]
You can find the coverage of regulations and standards for each Microsoft cloud service below as of February 2018:
- Office 365: Detailed information about Microsoft’s internal controls for and recommended customer actions for GDPR, ISO 27001, ISO 27018, NIST 800- 53, NIST 800- 171, and HIPAA
- Azure: Detailed information about Microsoft’s internal controls for ISO 27001 and ISO 27018
- Dynamics 365: Detailed information about Microsoft’s internal controls for NIST 800- 53; recommended customer actions for partial GDPR controls managed by organizations
[1] Note that Office 365 GCC customers can access Compliance Manager; however, users should evaluate whether to use the document upload feature of Compliance Manager, as the storage for document upload is compliant with Office 365 Tier C only. Compliance Manager is not yet available in sovereign clouds including Office 365 U.S. Government Community High (GCC High), Office 365 Department of Defense (DoD), Office 365 Operated by 21 Vianet, and Office 365 Germany.
[2] Coverage of regulations and standards in Compliance Manager varies by product. We will keep adding and updating the information in the future and our goal is to provide a similar experience of using Compliance Manager for all Microsoft Cloud services.
[3] Compliance Score is only available for Office 365 currently. Our goal is to provide Compliance Score for all Microsoft Cloud services in the near future.
[4] Compliance Manager is a dashboard that provides the Compliance Score and a summary of your data protection and compliance stature as well as recommendations to improve data protection and compliance. This is a recommendation; it is up to you to evaluate and validate the effectiveness of customer controls as per your regulatory environment. Recommendations from Compliance Manager and Compliance Score should not be interpreted as a guarantee of compliance.
In this mobile-first and cloud-first world, Microsoft is committed to build and maintain a partnership with you to meet your security, compliance, and privacy needs. When your organization’s data was on-premises, it was 100 percent your responsibility to meet all regulatory requirements. As you move your data to a Microsoft Cloud service, such as Office 365, Azure, or Dynamics 365, we partner with you to help you achieve compliance under the shared responsibility model.
To support your organization’s compliance journey when using Microsoft Cloud services, Microsoft released Compliance Manager Preview last November. Today, we are building upon this partnership by announcing thatis now generally available as an additional value for Azure, Dynamics 365, and Office 365 Business and Enterprise subscribers in public clouds[1].
Compliance Manager empowers your organization to manage your compliance activities from one place with three key capabilities:
- Helps you perform on-going risk assessments, now with Compliance Score
Compliance Manager is a cross-Microsoft Cloud services solution designed to help organizations meet complex compliance obligations, including the EU GDPR, ISO 27001, ISO 27018, NIST 800- 53, NIST 800- 171, and HIPAA[2].
It enables your organization to perform on-going risk assessments for what is identified as Microsoft’s responsibilities by evaluating detailed implementation and test details of our internal controls. We are committed to be transparent about how we process and protect your data so that you can trust Microsoft and leverage the technology we provide.
Compliance Manager dashboard with Compliance Score
We also provide you the information and tools to conduct self-assessment for your responsibilities of meeting regulatory requirements. Now with Compliance Score[3] —a new feature for Compliance Manager—you can gain visibility into your organization’s compliance stature with a risk-based score reference.
The Compliance Score is based on the operating effectiveness of internal controls managed by both Microsoft and you. Failure to implement different controls will have different levels of risk. We assign a weight to each control based on the level of risk involved when you do not implement a control or fail to pass the test of a control. From the detailed information page of each assessment, you can find an assigned risk-based score for each control item, and prioritize your tasks and make better implementation plans based on the risk involved.
- Provides you actionable insights, now from a certification/regulation view
One of the biggest pain points we heard from organizations is finding talent with expertise in both industrial compliance and technology solutions. Most of the time, compliance personnel have in-depth knowledge of industrial regulations and standards, while IT professionals have the technology tools that help the company to protect data. Because there is lack of connections between these two areas, meeting data protection and regulatory requirements becomes a very disjointed process.
To help reduce this challenge, Compliance Manager builds the connection between the data protection capabilities and the regulatory requirements, so now you know which technology solutions you can leverage to meet certain compliance obligations.
In response to feedback from customers, this product update re-organizes the control information from the “Microsoft control framework” view (e.g. MS-control AR-0104) to a “certification controls or regulatory article” view (e.g. ISO 27001:2013: C.5.1.a). Before, one Microsoft control corresponded to one or multiple certification controls or regulatory articles, and you needed to take many actions to implement one control. In the newly updated view, you can see customer actions for each certification or regulatory control, and the specific actions recommended for each control[4].
Detailed information page of an assessment
You still have the same experience for each control, i.e., finding customer actions with step-by-step guidance to guide you through implementing internal controls and developing business processes for your organization. We will keep the preview view (MS-control view) till the end of August 2018 for you to migrate the information into the new view.
- Simplifies your journey to manage compliance activities, now with the capability to create multiple assessments for each standard and regulation
According to the report, Cost of Compliance 2017 from Thomson Reuters, 32 percent of companies spend more than 4 hours per week creating and amending audit reports. It’s very time-consuming to collect evidence and demonstrate effective control implementation for auditing activities.
Compliance Manager enables you to assign, track, and record your compliance activities, so you can collaborate across teams and manage your documents for creating audit reports more easily.
By using group functionality, you can now create multiple assessments for any standard or regulation that is available to you in Compliance Manager by time, by teams, or by business units. For example, you can create a GDPR assessment for the 2018 group and another one for the 2019 group. Similarly, you can create an ISO 27001 assessment for your business units located in the U.S. and another one for your business units located in Europe. This functionality gives you a more robust way to manage compliance activities based on your organizational needs for performing risk assessments.
We are excited to launch Compliance Manager with these updates to make it a better experience for you. We’d like to hear your feedback on the product to keep improving functionality, adding new features, and enhancing existing ones. Sign in totoday using your Azure, Dynamics 365, or Office 365 account, and give us feedback via the Feedback button at the bottom right corner of Compliance Manager. You can also learn more about Compliance Manager in this, “Simplify your compliance journey with Service Trust Portal and Compliance Manager”, and on the Compliance Manager support page.
Work with a partner who knows GDPR
Microsoft works with partners globally to address customer needs around GDPR. We have several partners today offering Microsoft-based solutions that include an overall set of controls and capabilities to help customers meet their GDPR requirements. Here’s our list of global partners we currently work with to meet the growing demand for GDPR support.
Product scope[2]
You can find the coverage of regulations and standards for each Microsoft cloud service below as of February 2018:
- Office 365: Detailed information about Microsoft’s internal controls for and recommended customer actions for GDPR, ISO 27001, ISO 27018, NIST 800- 53, NIST 800- 171, and HIPAA
- Azure: Detailed information about Microsoft’s internal controls for ISO 27001 and ISO 27018
- Dynamics 365: Detailed information about Microsoft’s internal controls for NIST 800- 53; recommended customer actions for partial GDPR controls managed by organizations
[1] Note that Office 365 GCC customers can access Compliance Manager; however, users should evaluate whether to use the document upload feature of Compliance Manager, as the storage for document upload is compliant with Office 365 Tier C only. Compliance Manager is not yet available in sovereign clouds including Office 365 U.S. Government Community High (GCC High), Office 365 Department of Defense (DoD), Office 365 Operated by 21 Vianet, and Office 365 Germany.
[2] Coverage of regulations and standards in Compliance Manager varies by product. We will keep adding and updating the information in the future and our goal is to provide a similar experience of using Compliance Manager for all Microsoft Cloud services.
[3] Compliance Score is only available for Office 365 currently. Our goal is to provide Compliance Score for all Microsoft Cloud services in the near future.
[4] Compliance Manager is a dashboard that provides the Compliance Score and a summary of your data protection and compliance stature as well as recommendations to improve data protection and compliance. This is a recommendation; it is up to you to evaluate and validate the effectiveness of customer controls as per your regulatory environment. Recommendations from Compliance Manager and Compliance Score should not be interpreted as a guarantee of compliance.

We understand that shadow IT is a problem for many organizations. This is why we built Productivity App Discovery in Office 365 Cloud App Security. For those of you not familiar with this, it gives you the ability to understand what cloud services are being used in your organization that have similar functionality to Office 365. Today we are excited to announce enhancements to this feature based on feedback to help you do a more thorough investigation of the discovered apps.
The biggest changes to Productivity App Discovery revolve around providing user and IP address information. After you create a new report, the dashboard will show you a count of users as part of the summary and a new widget that shows you the top users and top addresses to help identify the most dominant users of cloud apps in your organization.
New look to Productivity App Discovery dashboard
You will also notice that the dashboard has three new tabs. Discovered apps, IP addresses, and Users. The Discovered apps tab shows you additional details for the discovered applications like the amount of traffic, the number of users and when the application was as seen. By clicking on one of the apps you can see additional details specific to that application like which users and IP addresses are accessing it, along with trend data. The discovered app tab also includes a way to create a query for specific apps that match your criteria. For example, you can create a query that shows you apps that were last seen after a specific date with more than 30 people using the app. By hovering over an app, you may see a subdomains popup. This will provide visibility into different instances of the app in use in the organization. For example, personal instance of Dropbox vs corporate.
 Discovered apps tab in Productivity App Discovery
Discovered apps tab in Productivity App Discovery
In the IP Addresses tab, you see the top 100 IPs accessing discovered cloud services. If you want more details on an IP, you can click on it to get a summary of the transactions and traffic along with the details of which apps that IP was accessing, and which users were using the IP.
 IP addresses tab in Productivity App Discovery
IP addresses tab in Productivity App Discovery
Lastly the Users tab shows you the top 100 users with same details as the IP Addresses tab. Here you can search for a specific user or click their name in the list and pivot the report to see a summary of their cloud services usage along with the specific apps they were using and the IP addresses.
 Users tab in Productivity App Discovery
Users tab in Productivity App Discovery
These enhancements are going to make investigating shadow IT and educating users on which cloud services are approved by the organization easier. If you own Office 365 E5 or the standalone SKU for Office 365 Cloud App Security you can check out the new features by logging in at https://portal.cloudappsecurity.com. To learn more about the new features check out the support article here. As always please reach out in the comments if you have questions, comments, or visit the uservoice site to suggest a feature made available in Office 365 Cloud App Security.
The following is provided from Microsoft Security and Compliance blogs at TechCommunity:
We understand that shadow IT is a problem for many organizations. This is why we built Productivity App Discovery in Office 365 Cloud App Security. For those of you not familiar with this, it gives you the ability to understand what cloud services are being used in your organization that have similar functionality to Office 365. Today we are excited to announce enhancements to this feature based on feedback to help you do a more thorough investigation of the discovered apps.
The biggest changes to Productivity App Discovery revolve around providing user and IP address information. After you create a new report, the dashboard will show you a count of users as part of the summary and a new widget that shows you the top users and top addresses to help identify the most dominant users of cloud apps in your organization.
New look to Productivity App Discovery dashboard
You will also notice that the dashboard has three new tabs. Discovered apps, IP addresses, and Users. The Discovered apps tab shows you additional details for the discovered applications like the amount of traffic, the number of users and when the application was as seen. By clicking on one of the apps you can see additional details specific to that application like which users and IP addresses are accessing it, along with trend data. The discovered app tab also includes a way to create a query for specific apps that match your criteria. For example, you can create a query that shows you apps that were last seen after a specific date with more than 30 people using the app. By hovering over an app, you may see a subdomains popup. This will provide visibility into different instances of the app in use in the organization. For example, personal instance of Dropbox vs corporate.
Discovered apps tab in Productivity App Discovery
In the IP Addresses tab, you see the top 100 IPs accessing discovered cloud services. If you want more details on an IP, you can click on it to get a summary of the transactions and traffic along with the details of which apps that IP was accessing, and which users were using the IP.
IP addresses tab in Productivity App Discovery
Lastly the Users tab shows you the top 100 users with same details as the IP Addresses tab. Here you can search for a specific user or click their name in the list and pivot the report to see a summary of their cloud services usage along with the specific apps they were using and the IP addresses.
Users tab in Productivity App Discovery
These enhancements are going to make investigating shadow IT and educating users on which cloud services are approved by the organization easier. If you own Office 365 E5 or the standalone SKU for Office 365 Cloud App Security you can check out the new features by logging in at https://portal.cloudappsecurity.com. To learn more about the new features check out the support article here. As always please reach out in the comments if you have questions, comments, or visit the uservoice site to suggest a feature made available in Office 365 Cloud App Security.
The above was provided from Microsoft Security and Compliance blogs at TechCommunity
We understand that shadow IT is a problem for many organizations. This is why we built Productivity App Discovery in Office 365 Cloud App Security. For those of you not familiar with this, it gives you the ability to understand what cloud services are being used in your organization that have similar functionality to Office 365. Today we are excited to announce enhancements to this feature based on feedback to help you do a more thorough investigation of the discovered apps.
The biggest changes to Productivity App Discovery revolve around providing user and IP address information. After you create a new report, the dashboard will show you a count of users as part of the summary and a new widget that shows you the top users and top addresses to help identify the most dominant users of cloud apps in your organization.
New look to Productivity App Discovery dashboard
You will also notice that the dashboard has three new tabs. Discovered apps, IP addresses, and Users. The Discovered apps tab shows you additional details for the discovered applications like the amount of traffic, the number of users and when the application was as seen. By clicking on one of the apps you can see additional details specific to that application like which users and IP addresses are accessing it, along with trend data. The discovered app tab also includes a way to create a query for specific apps that match your criteria. For example, you can create a query that shows you apps that were last seen after a specific date with more than 30 people using the app. By hovering over an app, you may see a subdomains popup. This will provide visibility into different instances of the app in use in the organization. For example, personal instance of Dropbox vs corporate.
Discovered apps tab in Productivity App Discovery
In the IP Addresses tab, you see the top 100 IPs accessing discovered cloud services. If you want more details on an IP, you can click on it to get a summary of the transactions and traffic along with the details of which apps that IP was accessing, and which users were using the IP.
IP addresses tab in Productivity App Discovery
Lastly the Users tab shows you the top 100 users with same details as the IP Addresses tab. Here you can search for a specific user or click their name in the list and pivot the report to see a summary of their cloud services usage along with the specific apps they were using and the IP addresses.
Users tab in Productivity App Discovery
These enhancements are going to make investigating shadow IT and educating users on which cloud services are approved by the organization easier. If you own Office 365 E5 or the standalone SKU for Office 365 Cloud App Security you can check out the new features by logging in at https://portal.cloudappsecurity.com. To learn more about the new features check out the support article here. As always please reach out in the comments if you have questions, comments, or visit the uservoice site to suggest a feature made available in Office 365 Cloud App Security.
We understand that shadow IT is a problem for many organizations. This is why we built Productivity App Discovery in Office 365 Cloud App Security. For those of you not familiar with this, it gives you the ability to understand what cloud services are being used in your organization that have similar functionality to Office 365. Today we are excited to announce enhancements to this feature based on feedback to help you do a more thorough investigation of the discovered apps.
The biggest changes to Productivity App Discovery revolve around providing user and IP address information. After you create a new report, the dashboard will show you a count of users as part of the summary and a new widget that shows you the top users and top addresses to help identify the most dominant users of cloud apps in your organization.
New look to Productivity App Discovery dashboard
You will also notice that the dashboard has three new tabs. Discovered apps, IP addresses, and Users. The Discovered apps tab shows you additional details for the discovered applications like the amount of traffic, the number of users and when the application was as seen. By clicking on one of the apps you can see additional details specific to that application like which users and IP addresses are accessing it, along with trend data. The discovered app tab also includes a way to create a query for specific apps that match your criteria. For example, you can create a query that shows you apps that were last seen after a specific date with more than 30 people using the app. By hovering over an app, you may see a subdomains popup. This will provide visibility into different instances of the app in use in the organization. For example, personal instance of Dropbox vs corporate.
Discovered apps tab in Productivity App Discovery
In the IP Addresses tab, you see the top 100 IPs accessing discovered cloud services. If you want more details on an IP, you can click on it to get a summary of the transactions and traffic along with the details of which apps that IP was accessing, and which users were using the IP.
IP addresses tab in Productivity App Discovery
Lastly the Users tab shows you the top 100 users with same details as the IP Addresses tab. Here you can search for a specific user or click their name in the list and pivot the report to see a summary of their cloud services usage along with the specific apps they were using and the IP addresses.
Users tab in Productivity App Discovery
These enhancements are going to make investigating shadow IT and educating users on which cloud services are approved by the organization easier. If you own Office 365 E5 or the standalone SKU for Office 365 Cloud App Security you can check out the new features by logging in at https://portal.cloudappsecurity.com. To learn more about the new features check out the support article here. As always please reach out in the comments if you have questions, comments, or visit the uservoice site to suggest a feature made available in Office 365 Cloud App Security.
We understand that shadow IT is a problem for many organizations. This is why we built Productivity App Discovery in Office 365 Cloud App Security. For those of you not familiar with this, it gives you the ability to understand what cloud services are being used in your organization that have similar functionality to Office 365. Today we are excited to announce enhancements to this feature based on feedback to help you do a more thorough investigation of the discovered apps.
The biggest changes to Productivity App Discovery revolve around providing user and IP address information. After you create a new report, the dashboard will show you a count of users as part of the summary and a new widget that shows you the top users and top addresses to help identify the most dominant users of cloud apps in your organization.
New look to Productivity App Discovery dashboard
You will also notice that the dashboard has three new tabs. Discovered apps, IP addresses, and Users. The Discovered apps tab shows you additional details for the discovered applications like the amount of traffic, the number of users and when the application was as seen. By clicking on one of the apps you can see additional details specific to that application like which users and IP addresses are accessing it, along with trend data. The discovered app tab also includes a way to create a query for specific apps that match your criteria. For example, you can create a query that shows you apps that were last seen after a specific date with more than 30 people using the app. By hovering over an app, you may see a subdomains popup. This will provide visibility into different instances of the app in use in the organization. For example, personal instance of Dropbox vs corporate.
Discovered apps tab in Productivity App Discovery
In the IP Addresses tab, you see the top 100 IPs accessing discovered cloud services. If you want more details on an IP, you can click on it to get a summary of the transactions and traffic along with the details of which apps that IP was accessing, and which users were using the IP.
IP addresses tab in Productivity App Discovery
Lastly the Users tab shows you the top 100 users with same details as the IP Addresses tab. Here you can search for a specific user or click their name in the list and pivot the report to see a summary of their cloud services usage along with the specific apps they were using and the IP addresses.
Users tab in Productivity App Discovery
These enhancements are going to make investigating shadow IT and educating users on which cloud services are approved by the organization easier. If you own Office 365 E5 or the standalone SKU for Office 365 Cloud App Security you can check out the new features by logging in at https://portal.cloudappsecurity.com. To learn more about the new features check out the support article here. As always please reach out in the comments if you have questions, comments, or visit the uservoice site to suggest a feature made available in Office 365 Cloud App Security.

The following is provided from Microsoft Security and Compliance blogs at TechCommunity:
Introduction:
Electronic communication and collaboration services[1] such as Outlook.com, Skype, Gmail, Slack, and OneDrive are not merely channels for communication between people, people and businesses, or people and automation (such as bots or support agents)[2]. They also help individuals manage their day thanks to services that are tightly integrated into the communications experience. These include calendar services, reminders, task management capabilities, travel planning, package tracking, and a great many other ways to help people do more with their time.
Providing these productivity and time-enhancing capabilities can, and should, be done without compromising the confidentiality of their communication and whilst respecting data protection[3].
Examples of productivity service capabilities
In this paper, we will use the three following examples of productivity-enhancing services:
- The user books a trip from Brussels to Cairo. They receive a flight itinerary via email. The email service, using data within the itinerary, adds the trip to the user’s calendar including flight times, hotel and car hire information, restaurant bookings, and other relevant travel data. It prompts the user to create an “out of office” message for the relevant time, helps to cancel or rearrange meetings that overlap with the trip, monitors flight status and alerts the user to any changes in flight arrival or departure times, and may even prompt the user to depart for the airport in time to catch their flight.
- The user receives an email from a colleague asking them to “send the presentation before noon on July 27th”. The email service recognizes that the user is being asked to complete a task to a deadline, and adds it to the user’s task list. As the deadline approaches, the service reminds the user of the request so that they do not miss the deadline for completion.
- The user orders a pair of shoes from Zalando. Zalando emails a receipt to the user which includes a tracking number for the shoes which will be arriving next Thursday. The email service recognizes the tracking number and adds a reminder to the user’s calendar for next Thursday. The service periodically monitors the progress of the delivery, alerting the user to the projected arrival date.
Message processing data flow:
To provide these productivity features from within the electronic communications service the content follows a conceptually simple flow:
Starting with “A” the message is received by the recipient’s email service. The message’s body and attachments are passed onto the data enrichment processor (“B”) whose goal is to examine and enrich the message or attachment to make better use of the user’s time, deliver capabilities that make them more effective or efficient, or deliver experiences they find valuable. The data enrichment processor has several steps, where each step performs a specific detection or enrichment. In the examples listed above, for instance, some of the steps include detecting that a message is a trip manifest, that it contains a shipping manifest or confirmation, or that it features a task for the user to complete. These are just some examples of possible enrichments for different types of data or experiences.
The enrichment processing steps use a variety of technologies to detect and extract what they require. These include simple regular expressions (such as matching a phone number in a message body or attachment), pattern matchers (flight manifest and other forms of “machine to human” communications are produced using consistent templates where logic can be written to detect the templates and extract the necessary data), detect and extract embedded schema.org annotations[4], and even very complicated machine learning systems that extract information from natural language text (such as our requested task example).
In addition to delivering the message to the user’s mailbox, they may also (“C”) update the user’s calendar (such as with the trip times, or date when the shoes are to be delivered) and the user’s list of tasks (such as the requested task example) in “D”. They may also interact with external services, such as subscribing to a data feed (“E”) of flight change notifications or services that notify subscribers of changes in travel times or package delivery timelines. When feeds are unavailable, the service may use a polling-based mechanism to periodically requests updates from other services, such as requesting flight updates from the airline or checking on progress of the user’s shoe order.
As with the detection of spam and malware, many of these detections or enrichments are probabilistic; the service cannot assert with certainty they are correct. While there are standards like schema.org where the sender can include the necessary metadata in the message (such as flight information, or package delivery information) so it is always correct, there will always be cases (such as task detection) where the receiving service must infer it from the readable content of the message body or attachment.
The updates, notifications, calendar entries, tasks, or other objects are presented to the user (“F”) who can indicate if the service was right or wrong in what it detected. The original message, the user’s judgement of what the service inferred correctly or incorrectly, and any subsequent correction, can all be added to a database of messages and correct or incorrect inferences (“G”) that are used to train the next version of the data enrichment processor. This allows the service to “learn” over time and become more effective.
All this processing is particularly important for messages as they are received and added to the recipient’s mailbox. Enriching the message before it is exposed to the user means that they can immediately see if it is a travel manifest, if it includes the delivery timeline for their shoes, or if they are being asked to do something. This helps the user be more productive and better judge how to spend their time. These enrichments are also performed, however, against already received and processed messages, such as the feed processor (“E”) and subsequent processing described above. This means messages that were missed by earlier iterations of the data enrichment logic will be correctly processed.
Messages are very dynamic. For instance, businesses frequently change the templates they use to send out travel manifests. Consequently, the communications and collaboration service must adapt quickly to such changes, lest the value of the productivity enhancements be reduced or eliminated altogether. For example, if a user is not being informed that flight times have changed, they may miss their flight; if they are not reminded to complete a task, they may miss an important deadline or commitment.
Privacy: data protection and confidentiality implications
Protecting both the personal data of senders and recipients, as well as the confidentiality of communications, during message processing (“A” – “F” above) can be done with no loss of efficacy for the data enrichment server since that service is acting like a stateless function. The service processes the message and creates new metadata containing the data extracted from the message. It may also create new calendar entries, tasks, feed subscriptions, or other artifacts which are associated with the user and used to deliver productivity-enriching experiences. As the recipient’s communication service allows processing and access to the content on their behalf, it is the user’s expectation that these services will enhance their productivity. Failing to process every message for every user risks limiting productivity benefits for users.
Protecting personal data and confidentiality during the model building phase (“G” – “H” above) is done by selection of algorithms and approaches that preserve privacy and confidentiality; those in which personal data is not retained or exposed (for example, selection of privacy preserving machine learning feature vectors) or by restricting the use of the communication to building productivity capabilities[5].
In both the processing phase (“A” – “F”) and the model building phase (“G” – “H”) it is impossible to gather consent from the sender and all recipients[6]. Most electronic communications rely on open standards (such as SMTP[7]), which do not include provisions for consent gathering (in large part because the traditional communications they were intended to replace was the postal service, in which the sender had no control over what happened to the communications once it was sent to the recipient). In addition, the communication is often asynchronous; requiring the sender and all recipients to consent to processing prior to the first recipient seeing it would introduce significant delays and poor user experiences[8], even if it were possible[9].
For model building (“G” – “H”) it is impossible for a model to benefit a single user or only the users involved in the communications. That model building (aka training) phase is essential for the machine learning algorithm to learn the template/patterns of communications, such as the format of the message from the airline with flight information. A typical user never receives enough instances of a templated message to train the processor. Even if they did, the productivity feature would not be enabled until they had received enough instances. Given how often templates change, this would mean the feature would seldom be able to recognize anything for a user. For instance, roughly the first ten times you receive a flight manifest from BA.COM for a single flight segment flight within Europe, the productivity feature would not work for you because it hadn’t seen enough instances to train a usable recognizer. After having seen enough messages, it would start to work for a specific carrier, format of message, and type of flight. If a message is from a different carrier it would fail, as the template is different. If you book a trip with two flight segments it would fail, as it has only seen single segment manifests until now. And if the airline changed the format of the message it would fail, as it has only seen the previous version – and so on. The feature provides value because it can learn the patterns from messages received by anyone, whilst persevering privacy and confidentiality (such as k-anonymization[10]) – in the same way a cashier in a grocery store learns how to process your groceries more efficiently and effectively, by dealing with all customers. If that cashier couldn’t apply learnings from processing other customers’ groceries, your own grocery orders would like be processed very slowly indeed.
References
[1] It is difficult to differentiate communication from collaboration, and messages from other collaboration artifacts. Consider a document being jointly authored by many people, each of whom leaves comments in the document to express ideas and input. Those same comments would be transmitted as email, chats, or through voice rather than comments in a document. Rather than treat them as separate, we recognize collaboration and communication as inked and refer to them interchangeably.
[2] https://venturebeat.com/2016/09/05/the-chatbot-revolution-in-customer-support/
[3] Privacy, the protection of personal data, and confidentiality are frequently treated as synonymous, but we draw a distinction. For the purposes of this paper we treat privacy as protecting knowledge of who a piece of data is about, and confidentiality as protecting that information. As an example, consider a piece of data that indicates Bob is interested in buying a car. Privacy can be achieved by removing any knowledge the data is about Bob; knowing simply that someone is interested in buying a car protects Bob’s privacy. Protecting confidentiality is preventing Bob’s data from being exposed to anyone but him. While, in this specific instance, Bob may only be concerned with the protection of his personal data, if the information were instead related to Microsoft’s interest in buying LinkedIn, Microsoft would be very interested in protecting the confidentiality of that data.
[4] http://schema.org/
[5] Services like Office365 that provide subscription-funded productivity services to users are incentivized to preserve the confidentiality of user data; the user is the customer, not the product.
[6] Note that most electronic communications are not person-to-person, they often involve many parties, up to thousands or tens of thousands in instances such as a large conference call or Q&A session.
[7] https://tools.ietf.org/html/rfc5321
[8] Consider an example in which I have never previously sent you an email, but then send you one. Your email service wants to scan that email for any requests I may be making, so it can create a task and reminder for you to respond. I am unaware your email service does this kind of processing and have not consented to it. To gain my consent, your email service would somehow need to get in touch (perhaps by sending me an email asking if it is ok for my message to you to be so processed).
[9] Often communications are sent to accounts that are no longer active. If I send an email to three people at a company, it is possible one of them may no longer be employed there and the message is therefore undeliverable. Even if it is delivered, the intended recipient cannot consent to processing because they are no longer able to access that account.
[10] https://dataprivacylab.org/dataprivacy/projects/kanonymity/paper3.pdf
The above was provided from Microsoft Security and Compliance blogs at TechCommunity
Introduction:
Electronic communication and collaboration services[1] such as Outlook.com, Skype, Gmail, Slack, and OneDrive are not merely channels for communication between people, people and businesses, or people and automation (such as bots or support agents)[2]. They also help individuals manage their day thanks to services that are tightly integrated into the communications experience. These include calendar services, reminders, task management capabilities, travel planning, package tracking, and a great many other ways to help people do more with their time.
Providing these productivity and time-enhancing capabilities can, and should, be done without compromising the confidentiality of their communication and whilst respecting data protection[3].
Examples of productivity service capabilities
In this paper, we will use the three following examples of productivity-enhancing services:
- The user books a trip from Brussels to Cairo. They receive a flight itinerary via email. The email service, using data within the itinerary, adds the trip to the user’s calendar including flight times, hotel and car hire information, restaurant bookings, and other relevant travel data. It prompts the user to create an “out of office” message for the relevant time, helps to cancel or rearrange meetings that overlap with the trip, monitors flight status and alerts the user to any changes in flight arrival or departure times, and may even prompt the user to depart for the airport in time to catch their flight.
- The user receives an email from a colleague asking them to “send the presentation before noon on July 27th”. The email service recognizes that the user is being asked to complete a task to a deadline, and adds it to the user’s task list. As the deadline approaches, the service reminds the user of the request so that they do not miss the deadline for completion.
- The user orders a pair of shoes from Zalando. Zalando emails a receipt to the user which includes a tracking number for the shoes which will be arriving next Thursday. The email service recognizes the tracking number and adds a reminder to the user’s calendar for next Thursday. The service periodically monitors the progress of the delivery, alerting the user to the projected arrival date.
Message processing data flow:
To provide these productivity features from within the electronic communications service the content follows a conceptually simple flow:
Starting with “A” the message is received by the recipient’s email service. The message’s body and attachments are passed onto the data enrichment processor (“B”) whose goal is to examine and enrich the message or attachment to make better use of the user’s time, deliver capabilities that make them more effective or efficient, or deliver experiences they find valuable. The data enrichment processor has several steps, where each step performs a specific detection or enrichment. In the examples listed above, for instance, some of the steps include detecting that a message is a trip manifest, that it contains a shipping manifest or confirmation, or that it features a task for the user to complete. These are just some examples of possible enrichments for different types of data or experiences.
The enrichment processing steps use a variety of technologies to detect and extract what they require. These include simple regular expressions (such as matching a phone number in a message body or attachment), pattern matchers (flight manifest and other forms of “machine to human” communications are produced using consistent templates where logic can be written to detect the templates and extract the necessary data), detect and extract embedded schema.org annotations[4], and even very complicated machine learning systems that extract information from natural language text (such as our requested task example).
In addition to delivering the message to the user’s mailbox, they may also (“C”) update the user’s calendar (such as with the trip times, or date when the shoes are to be delivered) and the user’s list of tasks (such as the requested task example) in “D”. They may also interact with external services, such as subscribing to a data feed (“E”) of flight change notifications or services that notify subscribers of changes in travel times or package delivery timelines. When feeds are unavailable, the service may use a polling-based mechanism to periodically requests updates from other services, such as requesting flight updates from the airline or checking on progress of the user’s shoe order.
As with the detection of spam and malware, many of these detections or enrichments are probabilistic; the service cannot assert with certainty they are correct. While there are standards like schema.org where the sender can include the necessary metadata in the message (such as flight information, or package delivery information) so it is always correct, there will always be cases (such as task detection) where the receiving service must infer it from the readable content of the message body or attachment.
The updates, notifications, calendar entries, tasks, or other objects are presented to the user (“F”) who can indicate if the service was right or wrong in what it detected. The original message, the user’s judgement of what the service inferred correctly or incorrectly, and any subsequent correction, can all be added to a database of messages and correct or incorrect inferences (“G”) that are used to train the next version of the data enrichment processor. This allows the service to “learn” over time and become more effective.
All this processing is particularly important for messages as they are received and added to the recipient’s mailbox. Enriching the message before it is exposed to the user means that they can immediately see if it is a travel manifest, if it includes the delivery timeline for their shoes, or if they are being asked to do something. This helps the user be more productive and better judge how to spend their time. These enrichments are also performed, however, against already received and processed messages, such as the feed processor (“E”) and subsequent processing described above. This means messages that were missed by earlier iterations of the data enrichment logic will be correctly processed.
Messages are very dynamic. For instance, businesses frequently change the templates they use to send out travel manifests. Consequently, the communications and collaboration service must adapt quickly to such changes, lest the value of the productivity enhancements be reduced or eliminated altogether. For example, if a user is not being informed that flight times have changed, they may miss their flight; if they are not reminded to complete a task, they may miss an important deadline or commitment.
Privacy: data protection and confidentiality implications
Protecting both the personal data of senders and recipients, as well as the confidentiality of communications, during message processing (“A” – “F” above) can be done with no loss of efficacy for the data enrichment server since that service is acting like a stateless function. The service processes the message and creates new metadata containing the data extracted from the message. It may also create new calendar entries, tasks, feed subscriptions, or other artifacts which are associated with the user and used to deliver productivity-enriching experiences. As the recipient’s communication service allows processing and access to the content on their behalf, it is the user’s expectation that these services will enhance their productivity. Failing to process every message for every user risks limiting productivity benefits for users.
Protecting personal data and confidentiality during the model building phase (“G” – “H” above) is done by selection of algorithms and approaches that preserve privacy and confidentiality; those in which personal data is not retained or exposed (for example, selection of privacy preserving machine learning feature vectors) or by restricting the use of the communication to building productivity capabilities[5].
In both the processing phase (“A” – “F”) and the model building phase (“G” – “H”) it is impossible to gather consent from the sender and all recipients[6]. Most electronic communications rely on open standards (such as SMTP[7]), which do not include provisions for consent gathering (in large part because the traditional communications they were intended to replace was the postal service, in which the sender had no control over what happened to the communications once it was sent to the recipient). In addition, the communication is often asynchronous; requiring the sender and all recipients to consent to processing prior to the first recipient seeing it would introduce significant delays and poor user experiences[8], even if it were possible[9].
For model building (“G” – “H”) it is impossible for a model to benefit a single user or only the users involved in the communications. That model building (aka training) phase is essential for the machine learning algorithm to learn the template/patterns of communications, such as the format of the message from the airline with flight information. A typical user never receives enough instances of a templated message to train the processor. Even if they did, the productivity feature would not be enabled until they had received enough instances. Given how often templates change, this would mean the feature would seldom be able to recognize anything for a user. For instance, roughly the first ten times you receive a flight manifest from BA.COM for a single flight segment flight within Europe, the productivity feature would not work for you because it hadn’t seen enough instances to train a usable recognizer. After having seen enough messages, it would start to work for a specific carrier, format of message, and type of flight. If a message is from a different carrier it would fail, as the template is different. If you book a trip with two flight segments it would fail, as it has only seen single segment manifests until now. And if the airline changed the format of the message it would fail, as it has only seen the previous version – and so on. The feature provides value because it can learn the patterns from messages received by anyone, whilst persevering privacy and confidentiality (such as k-anonymization[10]) – in the same way a cashier in a grocery store learns how to process your groceries more efficiently and effectively, by dealing with all customers. If that cashier couldn’t apply learnings from processing other customers’ groceries, your own grocery orders would like be processed very slowly indeed.
References
[1] It is difficult to differentiate communication from collaboration, and messages from other collaboration artifacts. Consider a document being jointly authored by many people, each of whom leaves comments in the document to express ideas and input. Those same comments would be transmitted as email, chats, or through voice rather than comments in a document. Rather than treat them as separate, we recognize collaboration and communication as inked and refer to them interchangeably.
[2] https://venturebeat.com/2016/09/05/the-chatbot-revolution-in-customer-support/
[3] Privacy, the protection of personal data, and confidentiality are frequently treated as synonymous, but we draw a distinction. For the purposes of this paper we treat privacy as protecting knowledge of who a piece of data is about, and confidentiality as protecting that information. As an example, consider a piece of data that indicates Bob is interested in buying a car. Privacy can be achieved by removing any knowledge the data is about Bob; knowing simply that someone is interested in buying a car protects Bob’s privacy. Protecting confidentiality is preventing Bob’s data from being exposed to anyone but him. While, in this specific instance, Bob may only be concerned with the protection of his personal data, if the information were instead related to Microsoft’s interest in buying LinkedIn, Microsoft would be very interested in protecting the confidentiality of that data.
[4] http://schema.org/
[5] Services like Office365 that provide subscription-funded productivity services to users are incentivized to preserve the confidentiality of user data; the user is the customer, not the product.
[6] Note that most electronic communications are not person-to-person, they often involve many parties, up to thousands or tens of thousands in instances such as a large conference call or Q&A session.
[7] https://tools.ietf.org/html/rfc5321
[8] Consider an example in which I have never previously sent you an email, but then send you one. Your email service wants to scan that email for any requests I may be making, so it can create a task and reminder for you to respond. I am unaware your email service does this kind of processing and have not consented to it. To gain my consent, your email service would somehow need to get in touch (perhaps by sending me an email asking if it is ok for my message to you to be so processed).
[9] Often communications are sent to accounts that are no longer active. If I send an email to three people at a company, it is possible one of them may no longer be employed there and the message is therefore undeliverable. Even if it is delivered, the intended recipient cannot consent to processing because they are no longer able to access that account.
[10] https://dataprivacylab.org/dataprivacy/projects/kanonymity/paper3.pdf
Introduction:
Electronic communication and collaboration services[1] such as Outlook.com, Skype, Gmail, Slack, and OneDrive are not merely channels for communication between people, people and businesses, or people and automation (such as bots or support agents)[2]. They also help individuals manage their day thanks to services that are tightly integrated into the communications experience. These include calendar services, reminders, task management capabilities, travel planning, package tracking, and a great many other ways to help people do more with their time.
Providing these productivity and time-enhancing capabilities can, and should, be done without compromising the confidentiality of their communication and whilst respecting data protection[3].
Examples of productivity service capabilities
In this paper, we will use the three following examples of productivity-enhancing services:
- The user books a trip from Brussels to Cairo. They receive a flight itinerary via email. The email service, using data within the itinerary, adds the trip to the user’s calendar including flight times, hotel and car hire information, restaurant bookings, and other relevant travel data. It prompts the user to create an “out of office” message for the relevant time, helps to cancel or rearrange meetings that overlap with the trip, monitors flight status and alerts the user to any changes in flight arrival or departure times, and may even prompt the user to depart for the airport in time to catch their flight.
- The user receives an email from a colleague asking them to “send the presentation before noon on July 27th”. The email service recognizes that the user is being asked to complete a task to a deadline, and adds it to the user’s task list. As the deadline approaches, the service reminds the user of the request so that they do not miss the deadline for completion.
- The user orders a pair of shoes from Zalando. Zalando emails a receipt to the user which includes a tracking number for the shoes which will be arriving next Thursday. The email service recognizes the tracking number and adds a reminder to the user’s calendar for next Thursday. The service periodically monitors the progress of the delivery, alerting the user to the projected arrival date.
Message processing data flow:
To provide these productivity features from within the electronic communications service the content follows a conceptually simple flow:
Starting with “A” the message is received by the recipient’s email service. The message’s body and attachments are passed onto the data enrichment processor (“B”) whose goal is to examine and enrich the message or attachment to make better use of the user’s time, deliver capabilities that make them more effective or efficient, or deliver experiences they find valuable. The data enrichment processor has several steps, where each step performs a specific detection or enrichment. In the examples listed above, for instance, some of the steps include detecting that a message is a trip manifest, that it contains a shipping manifest or confirmation, or that it features a task for the user to complete. These are just some examples of possible enrichments for different types of data or experiences.
The enrichment processing steps use a variety of technologies to detect and extract what they require. These include simple regular expressions (such as matching a phone number in a message body or attachment), pattern matchers (flight manifest and other forms of “machine to human” communications are produced using consistent templates where logic can be written to detect the templates and extract the necessary data), detect and extract embedded schema.org annotations[4], and even very complicated machine learning systems that extract information from natural language text (such as our requested task example).
In addition to delivering the message to the user’s mailbox, they may also (“C”) update the user’s calendar (such as with the trip times, or date when the shoes are to be delivered) and the user’s list of tasks (such as the requested task example) in “D”. They may also interact with external services, such as subscribing to a data feed (“E”) of flight change notifications or services that notify subscribers of changes in travel times or package delivery timelines. When feeds are unavailable, the service may use a polling-based mechanism to periodically requests updates from other services, such as requesting flight updates from the airline or checking on progress of the user’s shoe order.
As with the detection of spam and malware, many of these detections or enrichments are probabilistic; the service cannot assert with certainty they are correct. While there are standards like schema.org where the sender can include the necessary metadata in the message (such as flight information, or package delivery information) so it is always correct, there will always be cases (such as task detection) where the receiving service must infer it from the readable content of the message body or attachment.
The updates, notifications, calendar entries, tasks, or other objects are presented to the user (“F”) who can indicate if the service was right or wrong in what it detected. The original message, the user’s judgement of what the service inferred correctly or incorrectly, and any subsequent correction, can all be added to a database of messages and correct or incorrect inferences (“G”) that are used to train the next version of the data enrichment processor. This allows the service to “learn” over time and become more effective.
All this processing is particularly important for messages as they are received and added to the recipient’s mailbox. Enriching the message before it is exposed to the user means that they can immediately see if it is a travel manifest, if it includes the delivery timeline for their shoes, or if they are being asked to do something. This helps the user be more productive and better judge how to spend their time. These enrichments are also performed, however, against already received and processed messages, such as the feed processor (“E”) and subsequent processing described above. This means messages that were missed by earlier iterations of the data enrichment logic will be correctly processed.
Messages are very dynamic. For instance, businesses frequently change the templates they use to send out travel manifests. Consequently, the communications and collaboration service must adapt quickly to such changes, lest the value of the productivity enhancements be reduced or eliminated altogether. For example, if a user is not being informed that flight times have changed, they may miss their flight; if they are not reminded to complete a task, they may miss an important deadline or commitment.
Privacy: data protection and confidentiality implications
Protecting both the personal data of senders and recipients, as well as the confidentiality of communications, during message processing (“A” – “F” above) can be done with no loss of efficacy for the data enrichment server since that service is acting like a stateless function. The service processes the message and creates new metadata containing the data extracted from the message. It may also create new calendar entries, tasks, feed subscriptions, or other artifacts which are associated with the user and used to deliver productivity-enriching experiences. As the recipient’s communication service allows processing and access to the content on their behalf, it is the user’s expectation that these services will enhance their productivity. Failing to process every message for every user risks limiting productivity benefits for users.
Protecting personal data and confidentiality during the model building phase (“G” – “H” above) is done by selection of algorithms and approaches that preserve privacy and confidentiality; those in which personal data is not retained or exposed (for example, selection of privacy preserving machine learning feature vectors) or by restricting the use of the communication to building productivity capabilities[5].
In both the processing phase (“A” – “F”) and the model building phase (“G” – “H”) it is impossible to gather consent from the sender and all recipients[6]. Most electronic communications rely on open standards (such as SMTP[7]), which do not include provisions for consent gathering (in large part because the traditional communications they were intended to replace was the postal service, in which the sender had no control over what happened to the communications once it was sent to the recipient). In addition, the communication is often asynchronous; requiring the sender and all recipients to consent to processing prior to the first recipient seeing it would introduce significant delays and poor user experiences[8], even if it were possible[9].
For model building (“G” – “H”) it is impossible for a model to benefit a single user or only the users involved in the communications. That model building (aka training) phase is essential for the machine learning algorithm to learn the template/patterns of communications, such as the format of the message from the airline with flight information. A typical user never receives enough instances of a templated message to train the processor. Even if they did, the productivity feature would not be enabled until they had received enough instances. Given how often templates change, this would mean the feature would seldom be able to recognize anything for a user. For instance, roughly the first ten times you receive a flight manifest from BA.COM for a single flight segment flight within Europe, the productivity feature would not work for you because it hadn’t seen enough instances to train a usable recognizer. After having seen enough messages, it would start to work for a specific carrier, format of message, and type of flight. If a message is from a different carrier it would fail, as the template is different. If you book a trip with two flight segments it would fail, as it has only seen single segment manifests until now. And if the airline changed the format of the message it would fail, as it has only seen the previous version – and so on. The feature provides value because it can learn the patterns from messages received by anyone, whilst persevering privacy and confidentiality (such as k-anonymization[10]) – in the same way a cashier in a grocery store learns how to process your groceries more efficiently and effectively, by dealing with all customers. If that cashier couldn’t apply learnings from processing other customers’ groceries, your own grocery orders would like be processed very slowly indeed.
References
[1] It is difficult to differentiate communication from collaboration, and messages from other collaboration artifacts. Consider a document being jointly authored by many people, each of whom leaves comments in the document to express ideas and input. Those same comments would be transmitted as email, chats, or through voice rather than comments in a document. Rather than treat them as separate, we recognize collaboration and communication as inked and refer to them interchangeably.
[2] https://venturebeat.com/2016/09/05/the-chatbot-revolution-in-customer-support/
[3] Privacy, the protection of personal data, and confidentiality are frequently treated as synonymous, but we draw a distinction. For the purposes of this paper we treat privacy as protecting knowledge of who a piece of data is about, and confidentiality as protecting that information. As an example, consider a piece of data that indicates Bob is interested in buying a car. Privacy can be achieved by removing any knowledge the data is about Bob; knowing simply that someone is interested in buying a car protects Bob’s privacy. Protecting confidentiality is preventing Bob’s data from being exposed to anyone but him. While, in this specific instance, Bob may only be concerned with the protection of his personal data, if the information were instead related to Microsoft’s interest in buying LinkedIn, Microsoft would be very interested in protecting the confidentiality of that data.
[4] http://schema.org/
[5] Services like Office365 that provide subscription-funded productivity services to users are incentivized to preserve the confidentiality of user data; the user is the customer, not the product.
[6] Note that most electronic communications are not person-to-person, they often involve many parties, up to thousands or tens of thousands in instances such as a large conference call or Q&A session.
[7] https://tools.ietf.org/html/rfc5321
[8] Consider an example in which I have never previously sent you an email, but then send you one. Your email service wants to scan that email for any requests I may be making, so it can create a task and reminder for you to respond. I am unaware your email service does this kind of processing and have not consented to it. To gain my consent, your email service would somehow need to get in touch (perhaps by sending me an email asking if it is ok for my message to you to be so processed).
[9] Often communications are sent to accounts that are no longer active. If I send an email to three people at a company, it is possible one of them may no longer be employed there and the message is therefore undeliverable. Even if it is delivered, the intended recipient cannot consent to processing because they are no longer able to access that account.
[10] https://dataprivacylab.org/dataprivacy/projects/kanonymity/paper3.pdf
Introduction:
Electronic communication and collaboration services[1] such as Outlook.com, Skype, Gmail, Slack, and OneDrive are not merely channels for communication between people, people and businesses, or people and automation (such as bots or support agents)[2]. They also help individuals manage their day thanks to services that are tightly integrated into the communications experience. These include calendar services, reminders, task management capabilities, travel planning, package tracking, and a great many other ways to help people do more with their time.
Providing these productivity and time-enhancing capabilities can, and should, be done without compromising the confidentiality of their communication and whilst respecting data protection[3].
Examples of productivity service capabilities
In this paper, we will use the three following examples of productivity-enhancing services:
- The user books a trip from Brussels to Cairo. They receive a flight itinerary via email. The email service, using data within the itinerary, adds the trip to the user’s calendar including flight times, hotel and car hire information, restaurant bookings, and other relevant travel data. It prompts the user to create an “out of office” message for the relevant time, helps to cancel or rearrange meetings that overlap with the trip, monitors flight status and alerts the user to any changes in flight arrival or departure times, and may even prompt the user to depart for the airport in time to catch their flight.
- The user receives an email from a colleague asking them to “send the presentation before noon on July 27th”. The email service recognizes that the user is being asked to complete a task to a deadline, and adds it to the user’s task list. As the deadline approaches, the service reminds the user of the request so that they do not miss the deadline for completion.
- The user orders a pair of shoes from Zalando. Zalando emails a receipt to the user which includes a tracking number for the shoes which will be arriving next Thursday. The email service recognizes the tracking number and adds a reminder to the user’s calendar for next Thursday. The service periodically monitors the progress of the delivery, alerting the user to the projected arrival date.
Message processing data flow:
To provide these productivity features from within the electronic communications service the content follows a conceptually simple flow:
Starting with “A” the message is received by the recipient’s email service. The message’s body and attachments are passed onto the data enrichment processor (“B”) whose goal is to examine and enrich the message or attachment to make better use of the user’s time, deliver capabilities that make them more effective or efficient, or deliver experiences they find valuable. The data enrichment processor has several steps, where each step performs a specific detection or enrichment. In the examples listed above, for instance, some of the steps include detecting that a message is a trip manifest, that it contains a shipping manifest or confirmation, or that it features a task for the user to complete. These are just some examples of possible enrichments for different types of data or experiences.
The enrichment processing steps use a variety of technologies to detect and extract what they require. These include simple regular expressions (such as matching a phone number in a message body or attachment), pattern matchers (flight manifest and other forms of “machine to human” communications are produced using consistent templates where logic can be written to detect the templates and extract the necessary data), detect and extract embedded schema.org annotations[4], and even very complicated machine learning systems that extract information from natural language text (such as our requested task example).
In addition to delivering the message to the user’s mailbox, they may also (“C”) update the user’s calendar (such as with the trip times, or date when the shoes are to be delivered) and the user’s list of tasks (such as the requested task example) in “D”. They may also interact with external services, such as subscribing to a data feed (“E”) of flight change notifications or services that notify subscribers of changes in travel times or package delivery timelines. When feeds are unavailable, the service may use a polling-based mechanism to periodically requests updates from other services, such as requesting flight updates from the airline or checking on progress of the user’s shoe order.
As with the detection of spam and malware, many of these detections or enrichments are probabilistic; the service cannot assert with certainty they are correct. While there are standards like schema.org where the sender can include the necessary metadata in the message (such as flight information, or package delivery information) so it is always correct, there will always be cases (such as task detection) where the receiving service must infer it from the readable content of the message body or attachment.
The updates, notifications, calendar entries, tasks, or other objects are presented to the user (“F”) who can indicate if the service was right or wrong in what it detected. The original message, the user’s judgement of what the service inferred correctly or incorrectly, and any subsequent correction, can all be added to a database of messages and correct or incorrect inferences (“G”) that are used to train the next version of the data enrichment processor. This allows the service to “learn” over time and become more effective.
All this processing is particularly important for messages as they are received and added to the recipient’s mailbox. Enriching the message before it is exposed to the user means that they can immediately see if it is a travel manifest, if it includes the delivery timeline for their shoes, or if they are being asked to do something. This helps the user be more productive and better judge how to spend their time. These enrichments are also performed, however, against already received and processed messages, such as the feed processor (“E”) and subsequent processing described above. This means messages that were missed by earlier iterations of the data enrichment logic will be correctly processed.
Messages are very dynamic. For instance, businesses frequently change the templates they use to send out travel manifests. Consequently, the communications and collaboration service must adapt quickly to such changes, lest the value of the productivity enhancements be reduced or eliminated altogether. For example, if a user is not being informed that flight times have changed, they may miss their flight; if they are not reminded to complete a task, they may miss an important deadline or commitment.
Privacy: data protection and confidentiality implications
Protecting both the personal data of senders and recipients, as well as the confidentiality of communications, during message processing (“A” – “F” above) can be done with no loss of efficacy for the data enrichment server since that service is acting like a stateless function. The service processes the message and creates new metadata containing the data extracted from the message. It may also create new calendar entries, tasks, feed subscriptions, or other artifacts which are associated with the user and used to deliver productivity-enriching experiences. As the recipient’s communication service allows processing and access to the content on their behalf, it is the user’s expectation that these services will enhance their productivity. Failing to process every message for every user risks limiting productivity benefits for users.
Protecting personal data and confidentiality during the model building phase (“G” – “H” above) is done by selection of algorithms and approaches that preserve privacy and confidentiality; those in which personal data is not retained or exposed (for example, selection of privacy preserving machine learning feature vectors) or by restricting the use of the communication to building productivity capabilities[5].
In both the processing phase (“A” – “F”) and the model building phase (“G” – “H”) it is impossible to gather consent from the sender and all recipients[6]. Most electronic communications rely on open standards (such as SMTP[7]), which do not include provisions for consent gathering (in large part because the traditional communications they were intended to replace was the postal service, in which the sender had no control over what happened to the communications once it was sent to the recipient). In addition, the communication is often asynchronous; requiring the sender and all recipients to consent to processing prior to the first recipient seeing it would introduce significant delays and poor user experiences[8], even if it were possible[9].
For model building (“G” – “H”) it is impossible for a model to benefit a single user or only the users involved in the communications. That model building (aka training) phase is essential for the machine learning algorithm to learn the template/patterns of communications, such as the format of the message from the airline with flight information. A typical user never receives enough instances of a templated message to train the processor. Even if they did, the productivity feature would not be enabled until they had received enough instances. Given how often templates change, this would mean the feature would seldom be able to recognize anything for a user. For instance, roughly the first ten times you receive a flight manifest from BA.COM for a single flight segment flight within Europe, the productivity feature would not work for you because it hadn’t seen enough instances to train a usable recognizer. After having seen enough messages, it would start to work for a specific carrier, format of message, and type of flight. If a message is from a different carrier it would fail, as the template is different. If you book a trip with two flight segments it would fail, as it has only seen single segment manifests until now. And if the airline changed the format of the message it would fail, as it has only seen the previous version – and so on. The feature provides value because it can learn the patterns from messages received by anyone, whilst persevering privacy and confidentiality (such as k-anonymization[10]) – in the same way a cashier in a grocery store learns how to process your groceries more efficiently and effectively, by dealing with all customers. If that cashier couldn’t apply learnings from processing other customers’ groceries, your own grocery orders would like be processed very slowly indeed.
References
[1] It is difficult to differentiate communication from collaboration, and messages from other collaboration artifacts. Consider a document being jointly authored by many people, each of whom leaves comments in the document to express ideas and input. Those same comments would be transmitted as email, chats, or through voice rather than comments in a document. Rather than treat them as separate, we recognize collaboration and communication as inked and refer to them interchangeably.
[2] https://venturebeat.com/2016/09/05/the-chatbot-revolution-in-customer-support/
[3] Privacy, the protection of personal data, and confidentiality are frequently treated as synonymous, but we draw a distinction. For the purposes of this paper we treat privacy as protecting knowledge of who a piece of data is about, and confidentiality as protecting that information. As an example, consider a piece of data that indicates Bob is interested in buying a car. Privacy can be achieved by removing any knowledge the data is about Bob; knowing simply that someone is interested in buying a car protects Bob’s privacy. Protecting confidentiality is preventing Bob’s data from being exposed to anyone but him. While, in this specific instance, Bob may only be concerned with the protection of his personal data, if the information were instead related to Microsoft’s interest in buying LinkedIn, Microsoft would be very interested in protecting the confidentiality of that data.
[4] http://schema.org/
[5] Services like Office365 that provide subscription-funded productivity services to users are incentivized to preserve the confidentiality of user data; the user is the customer, not the product.
[6] Note that most electronic communications are not person-to-person, they often involve many parties, up to thousands or tens of thousands in instances such as a large conference call or Q&A session.
[7] https://tools.ietf.org/html/rfc5321
[8] Consider an example in which I have never previously sent you an email, but then send you one. Your email service wants to scan that email for any requests I may be making, so it can create a task and reminder for you to respond. I am unaware your email service does this kind of processing and have not consented to it. To gain my consent, your email service would somehow need to get in touch (perhaps by sending me an email asking if it is ok for my message to you to be so processed).
[9] Often communications are sent to accounts that are no longer active. If I send an email to three people at a company, it is possible one of them may no longer be employed there and the message is therefore undeliverable. Even if it is delivered, the intended recipient cannot consent to processing because they are no longer able to access that account.
[10] https://dataprivacylab.org/dataprivacy/projects/kanonymity/paper3.pdf
Introduction:
Electronic communication and collaboration services[1] such as Outlook.com, Skype, Gmail, Slack, and OneDrive are not merely channels for communication between people, people and businesses, or people and automation (such as bots or support agents)[2]. They also help individuals manage their day thanks to services that are tightly integrated into the communications experience. These include calendar services, reminders, task management capabilities, travel planning, package tracking, and a great many other ways to help people do more with their time.
Providing these productivity and time-enhancing capabilities can, and should, be done without compromising the confidentiality of their communication and whilst respecting data protection[3].
Examples of productivity service capabilities
In this paper, we will use the three following examples of productivity-enhancing services:
- The user books a trip from Brussels to Cairo. They receive a flight itinerary via email. The email service, using data within the itinerary, adds the trip to the user’s calendar including flight times, hotel and car hire information, restaurant bookings, and other relevant travel data. It prompts the user to create an “out of office” message for the relevant time, helps to cancel or rearrange meetings that overlap with the trip, monitors flight status and alerts the user to any changes in flight arrival or departure times, and may even prompt the user to depart for the airport in time to catch their flight.
- The user receives an email from a colleague asking them to “send the presentation before noon on July 27th”. The email service recognizes that the user is being asked to complete a task to a deadline, and adds it to the user’s task list. As the deadline approaches, the service reminds the user of the request so that they do not miss the deadline for completion.
- The user orders a pair of shoes from Zalando. Zalando emails a receipt to the user which includes a tracking number for the shoes which will be arriving next Thursday. The email service recognizes the tracking number and adds a reminder to the user’s calendar for next Thursday. The service periodically monitors the progress of the delivery, alerting the user to the projected arrival date.
Message processing data flow:
To provide these productivity features from within the electronic communications service the content follows a conceptually simple flow:
Starting with “A” the message is received by the recipient’s email service. The message’s body and attachments are passed onto the data enrichment processor (“B”) whose goal is to examine and enrich the message or attachment to make better use of the user’s time, deliver capabilities that make them more effective or efficient, or deliver experiences they find valuable. The data enrichment processor has several steps, where each step performs a specific detection or enrichment. In the examples listed above, for instance, some of the steps include detecting that a message is a trip manifest, that it contains a shipping manifest or confirmation, or that it features a task for the user to complete. These are just some examples of possible enrichments for different types of data or experiences.
The enrichment processing steps use a variety of technologies to detect and extract what they require. These include simple regular expressions (such as matching a phone number in a message body or attachment), pattern matchers (flight manifest and other forms of “machine to human” communications are produced using consistent templates where logic can be written to detect the templates and extract the necessary data), detect and extract embedded schema.org annotations[4], and even very complicated machine learning systems that extract information from natural language text (such as our requested task example).
In addition to delivering the message to the user’s mailbox, they may also (“C”) update the user’s calendar (such as with the trip times, or date when the shoes are to be delivered) and the user’s list of tasks (such as the requested task example) in “D”. They may also interact with external services, such as subscribing to a data feed (“E”) of flight change notifications or services that notify subscribers of changes in travel times or package delivery timelines. When feeds are unavailable, the service may use a polling-based mechanism to periodically requests updates from other services, such as requesting flight updates from the airline or checking on progress of the user’s shoe order.
As with the detection of spam and malware, many of these detections or enrichments are probabilistic; the service cannot assert with certainty they are correct. While there are standards like schema.org where the sender can include the necessary metadata in the message (such as flight information, or package delivery information) so it is always correct, there will always be cases (such as task detection) where the receiving service must infer it from the readable content of the message body or attachment.
The updates, notifications, calendar entries, tasks, or other objects are presented to the user (“F”) who can indicate if the service was right or wrong in what it detected. The original message, the user’s judgement of what the service inferred correctly or incorrectly, and any subsequent correction, can all be added to a database of messages and correct or incorrect inferences (“G”) that are used to train the next version of the data enrichment processor. This allows the service to “learn” over time and become more effective.
All this processing is particularly important for messages as they are received and added to the recipient’s mailbox. Enriching the message before it is exposed to the user means that they can immediately see if it is a travel manifest, if it includes the delivery timeline for their shoes, or if they are being asked to do something. This helps the user be more productive and better judge how to spend their time. These enrichments are also performed, however, against already received and processed messages, such as the feed processor (“E”) and subsequent processing described above. This means messages that were missed by earlier iterations of the data enrichment logic will be correctly processed.
Messages are very dynamic. For instance, businesses frequently change the templates they use to send out travel manifests. Consequently, the communications and collaboration service must adapt quickly to such changes, lest the value of the productivity enhancements be reduced or eliminated altogether. For example, if a user is not being informed that flight times have changed, they may miss their flight; if they are not reminded to complete a task, they may miss an important deadline or commitment.
Privacy: data protection and confidentiality implications
Protecting both the personal data of senders and recipients, as well as the confidentiality of communications, during message processing (“A” – “F” above) can be done with no loss of efficacy for the data enrichment server since that service is acting like a stateless function. The service processes the message and creates new metadata containing the data extracted from the message. It may also create new calendar entries, tasks, feed subscriptions, or other artifacts which are associated with the user and used to deliver productivity-enriching experiences. As the recipient’s communication service allows processing and access to the content on their behalf, it is the user’s expectation that these services will enhance their productivity. Failing to process every message for every user risks limiting productivity benefits for users.
Protecting personal data and confidentiality during the model building phase (“G” – “H” above) is done by selection of algorithms and approaches that preserve privacy and confidentiality; those in which personal data is not retained or exposed (for example, selection of privacy preserving machine learning feature vectors) or by restricting the use of the communication to building productivity capabilities[5].
In both the processing phase (“A” – “F”) and the model building phase (“G” – “H”) it is impossible to gather consent from the sender and all recipients[6]. Most electronic communications rely on open standards (such as SMTP[7]), which do not include provisions for consent gathering (in large part because the traditional communications they were intended to replace was the postal service, in which the sender had no control over what happened to the communications once it was sent to the recipient). In addition, the communication is often asynchronous; requiring the sender and all recipients to consent to processing prior to the first recipient seeing it would introduce significant delays and poor user experiences[8], even if it were possible[9].
For model building (“G” – “H”) it is impossible for a model to benefit a single user or only the users involved in the communications. That model building (aka training) phase is essential for the machine learning algorithm to learn the template/patterns of communications, such as the format of the message from the airline with flight information. A typical user never receives enough instances of a templated message to train the processor. Even if they did, the productivity feature would not be enabled until they had received enough instances. Given how often templates change, this would mean the feature would seldom be able to recognize anything for a user. For instance, roughly the first ten times you receive a flight manifest from BA.COM for a single flight segment flight within Europe, the productivity feature would not work for you because it hadn’t seen enough instances to train a usable recognizer. After having seen enough messages, it would start to work for a specific carrier, format of message, and type of flight. If a message is from a different carrier it would fail, as the template is different. If you book a trip with two flight segments it would fail, as it has only seen single segment manifests until now. And if the airline changed the format of the message it would fail, as it has only seen the previous version – and so on. The feature provides value because it can learn the patterns from messages received by anyone, whilst persevering privacy and confidentiality (such as k-anonymization[10]) – in the same way a cashier in a grocery store learns how to process your groceries more efficiently and effectively, by dealing with all customers. If that cashier couldn’t apply learnings from processing other customers’ groceries, your own grocery orders would like be processed very slowly indeed.
References
[1] It is difficult to differentiate communication from collaboration, and messages from other collaboration artifacts. Consider a document being jointly authored by many people, each of whom leaves comments in the document to express ideas and input. Those same comments would be transmitted as email, chats, or through voice rather than comments in a document. Rather than treat them as separate, we recognize collaboration and communication as inked and refer to them interchangeably.
[2] https://venturebeat.com/2016/09/05/the-chatbot-revolution-in-customer-support/
[3] Privacy, the protection of personal data, and confidentiality are frequently treated as synonymous, but we draw a distinction. For the purposes of this paper we treat privacy as protecting knowledge of who a piece of data is about, and confidentiality as protecting that information. As an example, consider a piece of data that indicates Bob is interested in buying a car. Privacy can be achieved by removing any knowledge the data is about Bob; knowing simply that someone is interested in buying a car protects Bob’s privacy. Protecting confidentiality is preventing Bob’s data from being exposed to anyone but him. While, in this specific instance, Bob may only be concerned with the protection of his personal data, if the information were instead related to Microsoft’s interest in buying LinkedIn, Microsoft would be very interested in protecting the confidentiality of that data.
[4] http://schema.org/
[5] Services like Office365 that provide subscription-funded productivity services to users are incentivized to preserve the confidentiality of user data; the user is the customer, not the product.
[6] Note that most electronic communications are not person-to-person, they often involve many parties, up to thousands or tens of thousands in instances such as a large conference call or Q&A session.
[7] https://tools.ietf.org/html/rfc5321
[8] Consider an example in which I have never previously sent you an email, but then send you one. Your email service wants to scan that email for any requests I may be making, so it can create a task and reminder for you to respond. I am unaware your email service does this kind of processing and have not consented to it. To gain my consent, your email service would somehow need to get in touch (perhaps by sending me an email asking if it is ok for my message to you to be so processed).
[9] Often communications are sent to accounts that are no longer active. If I send an email to three people at a company, it is possible one of them may no longer be employed there and the message is therefore undeliverable. Even if it is delivered, the intended recipient cannot consent to processing because they are no longer able to access that account.
[10] https://dataprivacylab.org/dataprivacy/projects/kanonymity/paper3.pdf
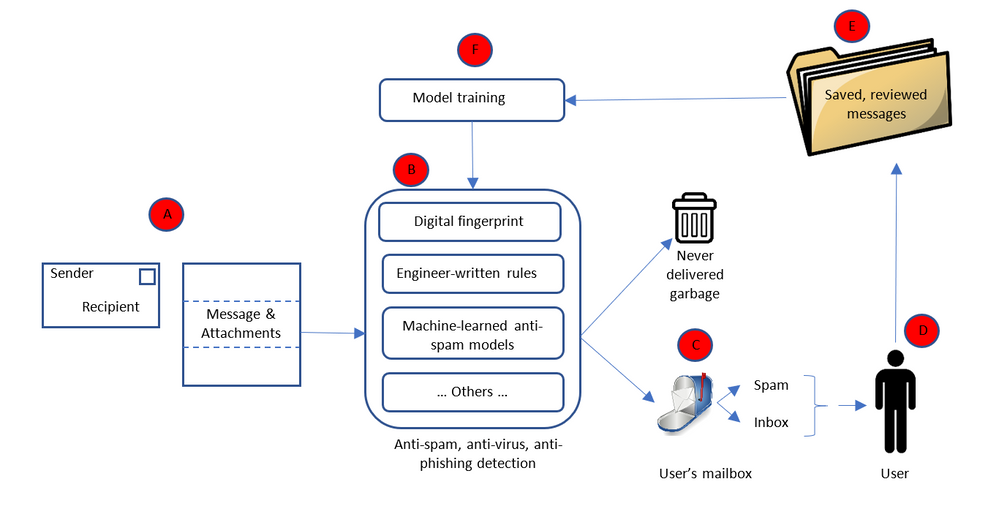
The following is provided from Microsoft Security and Compliance blogs at TechCommunity:
Electronic communication and collaboration services[1] such as Outlook.com, Skype, Gmail, Slack, and OneDrive carry valuable private and confidential communications that need protection. But these same services also provide a means for attackers to steal information or seize control of users’ computers for nefarious purposes, via viruses, worms, spam, phishing attacks, and other forms of malware.
Preventing the theft of user information and the dissemination of malware is a core feature of electronic communication and collaboration services. This requires significant processing of users’ communications and data both in-transit and after delivery. This processing can and should be done without compromising the user’s privacy or the confidentiality of their communications[2].
Message processing data flow:
To protect against malware distributed via electronic communications and collaboration systems such as email servers[3], the content follows a conceptually simple flow.
Starting with “A” the message is received by the recipient’s email service. The message’s envelope, as well as the message contents and any attachments, are passed on to the anti-malware portion of the email service (“B”) which determines whether or not the message is malware. Based on what the anti-malware service determines, the message is delivered to the user as appropriate (“C”). Some messages are determined to be malware with near certainty and are never delivered to the user. Instead they are deleted as quickly as possible[4]. Some messages are likely to be spam, however the service is not always certain. So the message is delivered to the user’s mailbox but into their spam/junk-mail folder. The remaining valid messages are delivered to the user’s inbox. The service can never determine with absolute certainty whether or not a message is malicious; it is always a probabilistic assessment. If the service is wrong either way; i.e. the user is exposed to malware or the user indicates that a message originally thought to be spam is not, the message may be added to a database of messages (“E”) used to train the next version of the anti-malware logic (“F”), thus permitting the system to “learn” over time and become more effective.
Clearly this entire process entails considerable processing of the messages. The types of processing are diverse and done in two key phases: message processing (“A” – “D”) and model building (“E” – “F”).
Anti-malware is particularly important for in-transit messages because attacks most typically enter the service through communications being transmitted. It is, however, also performed against already received and processed messages. As new attacks are identified – usually after the attack has been launched and some infected content has evaded the filters and been delivered to users – the anti-malware service is updated to defend against those attacks, and the service is rerun against recently delivered message to retroactively remove instances of said attack.
Processing message:
The types of processing done on messages to determine whether or not they are malicious include simple rules (e.g. messages without senders are likely not valid), reputations systems (messages from a certain set of IP addresses or senders are likely not valid, such as lists managed by the Spamhaus project[5]), digital thumbprints (comparing the thumbprint of the message or attachment to the thumbprints of known bad messages), honey pots (email addresses with no user and thus mailboxes that could never get any valid messages – anything delivered to them is spam or malware), and complex machine-learned models which process the contents of the message or the attachment[6]. As new forms of attack are encountered, new forms of defense must be quickly developed to keep users safe.
This requires processing of the message envelope, body, and attachment. For example:
- Message envelopes indicate not only the message recipient but also the supposed sender, and the server path which the message followed to reach the recipient. This is critical, not only to determine the recipient (needed to ensure the message is delivered to the intended recipients), but also to determine how probable it is that the sender is who they claim to be. It is common for attackers to “spoof” a sender, i.e. pretend they are a certain sender even though they are not. Knowing the path taken by the message can help determine if it has been sent by a spoof sender. For example, if a message originates from a trusted sending service which verifies the identity of the sender, then passes through a series of trusted intermediate services to the destination, the probability that the sender has been spoofed is much lower.
- Message bodies are among the most critical elements of the message which need to be processed to determine if the message is likely spam or a phishing attack. For example, text about “great deals on pharmaceuticals” is often indicative of spam. Without processing the body of the message, it is impossible to determine this. Attackers know that defenders watch out for such phrases, so they often try to hide them as text within an image. To the reader this looks similar, but defenders must run the images through optical character recognition algorithms to convert the images into text that can then be compared against a set of suspicious phrases. For example:
Another example of message body analysis is comparing the text of hyper-links to the URL. If a hyperlink’s text says “Click here to reset your Facebook password” but the URL points to “http://12345.contoso.com“, it is likely a phishing attack because Facebook password reset links should never be any URL other a correct Facebook one. Because most users do not check the URL before clicking on the hyperlink, it is important to protect them from such attacks. Without processing the message body, this is impossible.
- It is equally important to analyze attachments; otherwise attackers use them to deliver malicious payloads or contents to users. Attachments can be executables that open a user’s computer to attacker control. They can also be phishing attacks with the mismatched hyperlink text and URL scenario we described above embedded into the attachment. Any attack in the body of a message can appear in an attachment, and attachments can include additional forms of attack.
Model building:
Model building is the portion of machine learning in which the logic that does the evaluation is updated. It is the “learning” part of the machine learning; where the evaluation algorithm is updated based on new data so that it produces the desired output, not only based on data and results it has previous seen and been trained on, but also based on any new data or results.
The entire computer science sub-discipline of machine learning is the science of learning algorithms, and of this training phase, so a full treatise is beyond the scope of this paper. Generally speaking however, learning algorithms for detecting malware can be developed that respect the privacy of recipients because what is necessary is an understanding of the attack and the pattern of the attack, not the victims of that attack.
Privacy: data protection and confidentiality implications
Protecting the personal data of both sender and recipients, and communications confidentiality, during message processing (“A” – “D” above) can be done without diminishing the efficacy of the anti-malware service because that service acts as a stateless function. The service process the message and creates new metadata indicating whether or not the message should be delivered, without retaining any knowledge of the contents of the message and without exposing the message to anyone except the intended recipients. The recipient’s communication service processes and accesses the content on behalf of the recipient; and it is the recipient’s expectation to be protected against spam and malicious communications.. Failing to process every user’s every message would expose the entire service, and all its users, to known infections, which would be irresponsible.
Protecting personal data and confidentiality during the model building phase (“E” – “F” above) is done by a selection of algorithms and approaches that preserve privacy and confidentiality, those in which personal data is not retained or exposed (for example, selection of privacy preserving machine learning feature vectors), by restricting the use of the communication to building anti-malware capabilities[7], or by building user-specific models which solely benefit that user. The first two techniques have been used historically, but the third is becoming increasingly common as users’ expectations of what qualifies as nuisance communications (i.e. spam) become more individualized[8].
Using communication data for model building in anti-malware capabilities is done without explicit user consent. Malware is an ongoing struggle between attackers and the people providing the communications safety service, with attackers trying to find ways to get messages past the safety service. As new attacks emerge the safety service must respond quickly[9], using as much information as is available (which often necessitates sharing information with the anti-malware elements of other services). Attackers are increasingly using machine learning to create and launch attacks[10], requiring defenders to respond in kind with increasingly advanced machine learning-based defenses. One way to do this is to automate the creation of new versions of the anti-malware model so the service quickly inoculates all users against new attacks. The effectiveness of anti-malware depends on knowing about, and inoculating all users against, these attacks. This data can be used without exposing personal data or compromising confidentiality. All users of a service, and the entire service itself, are at risk if we fail to constantly process content in order to detect new forms of infection for every user. Similar to failing to inoculate a few members of a large population against an infectious disease, failing to process all users against these attacks would be irresponsible and would ultimately put the entire population at risk.
For anti-malware it important to note that the sender is generally malicious, and unlikely to grant consent to build better defenses against their attack. Requiring consent from all parties will make it impossible for services to provide a safe, secure, and nuisance-free communications and collaboration environment for all.
[1] It is difficult to differentiate between communication and collaboration, or between messages and other collaboration artifacts. Consider a document jointly authored by many people, each of whom leaves comments in the document to express ideas and input. Those same comments could be transmitted as email, chats, or through voice rather than comments in a document. Rather than treat them as separate, we recognize collaboration and communication as linked and refer to them interchangeably.
[2] Privacy, protection of personal data and confidentiality are frequently treated as synonymous, but we draw a distinction. For the purposes of this paper we treat data protection as the act of protecting knowledge of who a piece of data is about, and confidentiality as protecting that information. For example, consider a piece of data that indicates Bob is interested in buying a car. Data protection can be achieved by removing any knowledge that the data is about Bob; knowing simply that someone is interested in buying a car protects Bob’s privacy. Protecting confidentiality is preventing Bob’s data from being exposed to anyone but him. In this specific instance, Bob may only be concerned with protecting his personal data. However, if the information related to Microsoft’s interest in buying LinkedIn, Microsoft would be very interested in protecting the confidentiality of that data.
[3] Henceforth in this paper we will refer to this as an email service, but it is understood that similar problems and solutions apply to other communication and collaboration services.
[4] A staggering 77.8% of all messages sent to an email service are spam, with 90.4% of them being identified as such with sufficient certainty to prevent them ever being delivered to users.
[5] https://www.spamhaus.org/
[6] Use of machine learning in anti-spam services is one of the oldest, most pervasive, and most useful applications of that technology, dating back to at least 1998 (http://robotics.stanford.edu/users/sahami/papers-dir/spam.pdf)
[7] Services like Office365 that provide subscription-funded productivity services to users are incentivized to preserve the confidentiality of user data; the user is the customer, not the product.
[8] To my daughter, communications about new Lego toys are not a nuisance, they are interesting and desirable. However to me they are an imposition.
[9] Today, a typical spam campaign lasts under an hour. Yet in that time it gets through often enough to make it worthwhile to the attacker.
[10] https://erpscan.com/press-center/blog/machine-learning-for-cybercriminals
– Jim Kleewein, Technical Fellow, Microsoft
The above was provided from Microsoft Security and Compliance blogs at TechCommunity
Electronic communication and collaboration services[1] such as Outlook.com, Skype, Gmail, Slack, and OneDrive carry valuable private and confidential communications that need protection. But these same services also provide a means for attackers to steal information or seize control of users’ computers for nefarious purposes, via viruses, worms, spam, phishing attacks, and other forms of malware.
Preventing the theft of user information and the dissemination of malware is a core feature of electronic communication and collaboration services. This requires significant processing of users’ communications and data both in-transit and after delivery. This processing can and should be done without compromising the user’s privacy or the confidentiality of their communications[2].
Message processing data flow:
To protect against malware distributed via electronic communications and collaboration systems such as email servers[3], the content follows a conceptually simple flow.
Starting with “A” the message is received by the recipient’s email service. The message’s envelope, as well as the message contents and any attachments, are passed on to the anti-malware portion of the email service (“B”) which determines whether or not the message is malware. Based on what the anti-malware service determines, the message is delivered to the user as appropriate (“C”). Some messages are determined to be malware with near certainty and are never delivered to the user. Instead they are deleted as quickly as possible[4]. Some messages are likely to be spam, however the service is not always certain. So the message is delivered to the user’s mailbox but into their spam/junk-mail folder. The remaining valid messages are delivered to the user’s inbox. The service can never determine with absolute certainty whether or not a message is malicious; it is always a probabilistic assessment. If the service is wrong either way; i.e. the user is exposed to malware or the user indicates that a message originally thought to be spam is not, the message may be added to a database of messages (“E”) used to train the next version of the anti-malware logic (“F”), thus permitting the system to “learn” over time and become more effective.
Clearly this entire process entails considerable processing of the messages. The types of processing are diverse and done in two key phases: message processing (“A” – “D”) and model building (“E” – “F”).
Anti-malware is particularly important for in-transit messages because attacks most typically enter the service through communications being transmitted. It is, however, also performed against already received and processed messages. As new attacks are identified – usually after the attack has been launched and some infected content has evaded the filters and been delivered to users – the anti-malware service is updated to defend against those attacks, and the service is rerun against recently delivered message to retroactively remove instances of said attack.
Processing message:
The types of processing done on messages to determine whether or not they are malicious include simple rules (e.g. messages without senders are likely not valid), reputations systems (messages from a certain set of IP addresses or senders are likely not valid, such as lists managed by the Spamhaus project[5]), digital thumbprints (comparing the thumbprint of the message or attachment to the thumbprints of known bad messages), honey pots (email addresses with no user and thus mailboxes that could never get any valid messages – anything delivered to them is spam or malware), and complex machine-learned models which process the contents of the message or the attachment[6]. As new forms of attack are encountered, new forms of defense must be quickly developed to keep users safe.
This requires processing of the message envelope, body, and attachment. For example:
- Message envelopes indicate not only the message recipient but also the supposed sender, and the server path which the message followed to reach the recipient. This is critical, not only to determine the recipient (needed to ensure the message is delivered to the intended recipients), but also to determine how probable it is that the sender is who they claim to be. It is common for attackers to “spoof” a sender, i.e. pretend they are a certain sender even though they are not. Knowing the path taken by the message can help determine if it has been sent by a spoof sender. For example, if a message originates from a trusted sending service which verifies the identity of the sender, then passes through a series of trusted intermediate services to the destination, the probability that the sender has been spoofed is much lower.
- Message bodies are among the most critical elements of the message which need to be processed to determine if the message is likely spam or a phishing attack. For example, text about “great deals on pharmaceuticals” is often indicative of spam. Without processing the body of the message, it is impossible to determine this. Attackers know that defenders watch out for such phrases, so they often try to hide them as text within an image. To the reader this looks similar, but defenders must run the images through optical character recognition algorithms to convert the images into text that can then be compared against a set of suspicious phrases. For example:
Another example of message body analysis is comparing the text of hyper-links to the URL. If a hyperlink’s text says “Click here to reset your Facebook password” but the URL points to “http://12345.contoso.com“, it is likely a phishing attack because Facebook password reset links should never be any URL other a correct Facebook one. Because most users do not check the URL before clicking on the hyperlink, it is important to protect them from such attacks. Without processing the message body, this is impossible.
- It is equally important to analyze attachments; otherwise attackers use them to deliver malicious payloads or contents to users. Attachments can be executables that open a user’s computer to attacker control. They can also be phishing attacks with the mismatched hyperlink text and URL scenario we described above embedded into the attachment. Any attack in the body of a message can appear in an attachment, and attachments can include additional forms of attack.
Model building:
Model building is the portion of machine learning in which the logic that does the evaluation is updated. It is the “learning” part of the machine learning; where the evaluation algorithm is updated based on new data so that it produces the desired output, not only based on data and results it has previous seen and been trained on, but also based on any new data or results.
The entire computer science sub-discipline of machine learning is the science of learning algorithms, and of this training phase, so a full treatise is beyond the scope of this paper. Generally speaking however, learning algorithms for detecting malware can be developed that respect the privacy of recipients because what is necessary is an understanding of the attack and the pattern of the attack, not the victims of that attack.
Privacy: data protection and confidentiality implications
Protecting the personal data of both sender and recipients, and communications confidentiality, during message processing (“A” – “D” above) can be done without diminishing the efficacy of the anti-malware service because that service acts as a stateless function. The service process the message and creates new metadata indicating whether or not the message should be delivered, without retaining any knowledge of the contents of the message and without exposing the message to anyone except the intended recipients. The recipient’s communication service processes and accesses the content on behalf of the recipient; and it is the recipient’s expectation to be protected against spam and malicious communications.. Failing to process every user’s every message would expose the entire service, and all its users, to known infections, which would be irresponsible.
Protecting personal data and confidentiality during the model building phase (“E” – “F” above) is done by a selection of algorithms and approaches that preserve privacy and confidentiality, those in which personal data is not retained or exposed (for example, selection of privacy preserving machine learning feature vectors), by restricting the use of the communication to building anti-malware capabilities[7], or by building user-specific models which solely benefit that user. The first two techniques have been used historically, but the third is becoming increasingly common as users’ expectations of what qualifies as nuisance communications (i.e. spam) become more individualized[8].
Using communication data for model building in anti-malware capabilities is done without explicit user consent. Malware is an ongoing struggle between attackers and the people providing the communications safety service, with attackers trying to find ways to get messages past the safety service. As new attacks emerge the safety service must respond quickly[9], using as much information as is available (which often necessitates sharing information with the anti-malware elements of other services). Attackers are increasingly using machine learning to create and launch attacks[10], requiring defenders to respond in kind with increasingly advanced machine learning-based defenses. One way to do this is to automate the creation of new versions of the anti-malware model so the service quickly inoculates all users against new attacks. The effectiveness of anti-malware depends on knowing about, and inoculating all users against, these attacks. This data can be used without exposing personal data or compromising confidentiality. All users of a service, and the entire service itself, are at risk if we fail to constantly process content in order to detect new forms of infection for every user. Similar to failing to inoculate a few members of a large population against an infectious disease, failing to process all users against these attacks would be irresponsible and would ultimately put the entire population at risk.
For anti-malware it important to note that the sender is generally malicious, and unlikely to grant consent to build better defenses against their attack. Requiring consent from all parties will make it impossible for services to provide a safe, secure, and nuisance-free communications and collaboration environment for all.
[1] It is difficult to differentiate between communication and collaboration, or between messages and other collaboration artifacts. Consider a document jointly authored by many people, each of whom leaves comments in the document to express ideas and input. Those same comments could be transmitted as email, chats, or through voice rather than comments in a document. Rather than treat them as separate, we recognize collaboration and communication as linked and refer to them interchangeably.
[2] Privacy, protection of personal data and confidentiality are frequently treated as synonymous, but we draw a distinction. For the purposes of this paper we treat data protection as the act of protecting knowledge of who a piece of data is about, and confidentiality as protecting that information. For example, consider a piece of data that indicates Bob is interested in buying a car. Data protection can be achieved by removing any knowledge that the data is about Bob; knowing simply that someone is interested in buying a car protects Bob’s privacy. Protecting confidentiality is preventing Bob’s data from being exposed to anyone but him. In this specific instance, Bob may only be concerned with protecting his personal data. However, if the information related to Microsoft’s interest in buying LinkedIn, Microsoft would be very interested in protecting the confidentiality of that data.
[3] Henceforth in this paper we will refer to this as an email service, but it is understood that similar problems and solutions apply to other communication and collaboration services.
[4] A staggering 77.8% of all messages sent to an email service are spam, with 90.4% of them being identified as such with sufficient certainty to prevent them ever being delivered to users.
[5] https://www.spamhaus.org/
[6] Use of machine learning in anti-spam services is one of the oldest, most pervasive, and most useful applications of that technology, dating back to at least 1998 (http://robotics.stanford.edu/users/sahami/papers-dir/spam.pdf)
[7] Services like Office365 that provide subscription-funded productivity services to users are incentivized to preserve the confidentiality of user data; the user is the customer, not the product.
[8] To my daughter, communications about new Lego toys are not a nuisance, they are interesting and desirable. However to me they are an imposition.
[9] Today, a typical spam campaign lasts under an hour. Yet in that time it gets through often enough to make it worthwhile to the attacker.
[10] https://erpscan.com/press-center/blog/machine-learning-for-cybercriminals
– Jim Kleewein, Technical Fellow, Microsoft







